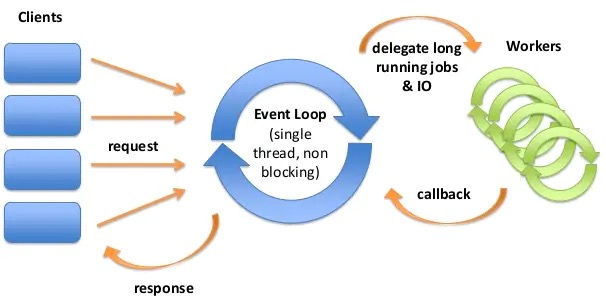
那一年有个程序员在github上撕心裂肺痛首疾呼
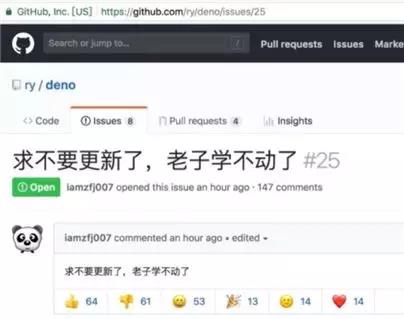
这句呐喊,喊出了多少程序员内心的苦楚,行业更新迭代太快,而年龄在不断增长,精力在下降,尤其现如今的内卷文化,怎么才能不掉队,保持竞争力?似乎唯有保持学习能力一条路。
我们是怎么学习的呢?学习的效果如何?需要去对学习有一定的元认知能力。
李笑来老师有个专栏,叫学习学习再学习。意思是讲先把学习这件事学习会了,再去学习其他知识。
我也一直在反思自己的学习能力,学习效果与速度,所以也一直在学习怎么学习,怎么学习才有效果,脱离低级学习效能。毕竟学习本身不仅对自身有帮助,也是家中无矿普通大众唯一可以传承给后代的财富,知识时代,缺什么也不能缺少学习能力。
功夫
我们学习的动机是什么?
一开始我们靠兴趣,但是兴趣多变;然后我们追新知,发现新知进化得比我们学习的速度还快;之后我们回身去读经典,却发现经典一辈子也读不完;于是我们开始寻求底层逻辑。
然而底层逻辑是高度抽象的,人类对抽象的认知都是非常困难的,幸运的是所有对抽象的认知都是源于对大量具体事物认知的抽象。
我们一般都不是骨骼清奇的天才,大多数时候只能渐修顿悟。就算是真经放在眼前,也没有识货的能力。
举个切身经历的案例,在我刚入职场时,那时我还很痴迷于阅读源码,一天我灵机一动,学生时代就倒腾了几年的web开发,都是跑在web container中的,为何不看看tomcat源码呢,下班看,上班干完手上活也看。一天领导问我在干吗,我兴致勃勃地说在看tomcat源码,写得真精妙。
领导把我叫到一边,语重心长地说,学习源码是不错,但对我们当前工作有直接帮助吗?我们开发游戏,用的是TCP协议,使用的是mina、netty网络框架,如果现在项目中要准备使用web了,再看也不迟。就算你现在看了,以后我们真用上,其他人去学习,你也不一定比他们提前多少。
“切,又忽悠我多干活,压榨”。这是我当时第一反应。你觉得这是真经吗?
领导的这番教导,我也是过了很久才慢慢醒悟。是什么底层认知逻辑,且看文末总结。
因此我们还是得踏踏实实地积累基础知识,同时,需要勤于思考,学会抽象,学会抓本质。
花功夫,事上修。否则读遍经书也枉然。
如何学习
学习一样技能,需要经过三个过程
1、编码:知道并理解,形成一些潜在的心理表征
2、巩固:强化心理表征,通过遗忘,再考试,再练习不断地被挑战
3、检索:学以致用
细化一下这个过程
大概会经过这几个步骤:获取、理解、拓展、纠错、应用
获取
不再像过去贫瘠时代,获取知识本身的难度,现今是如何面对信息大爆炸时代,过滤出精品。
获取知识的两个要点:
1、速度
2、质量
对于速度,有几个方法:
首先让自己变成一个文字型学习者,现在有视频、音频等多媒体信息,而文字是最快速的获取方式。回想微信聊天,是看文字快还是语音快?
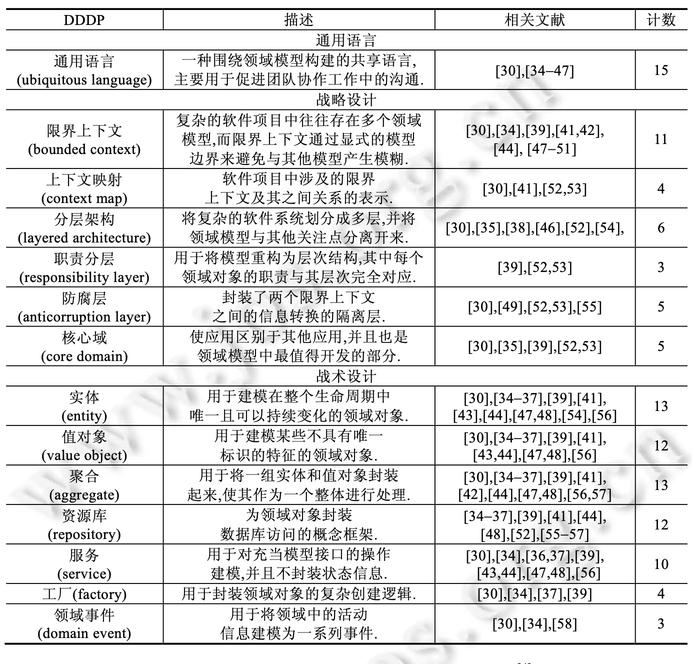
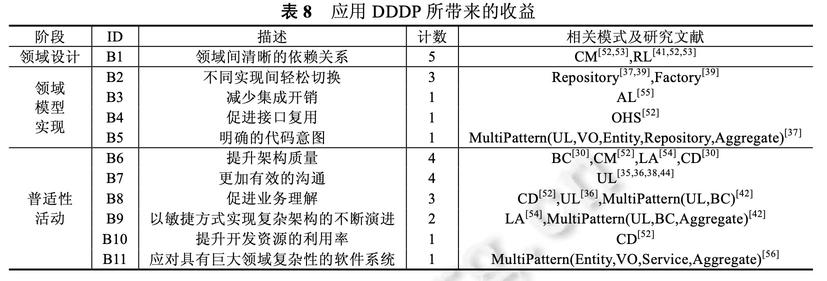
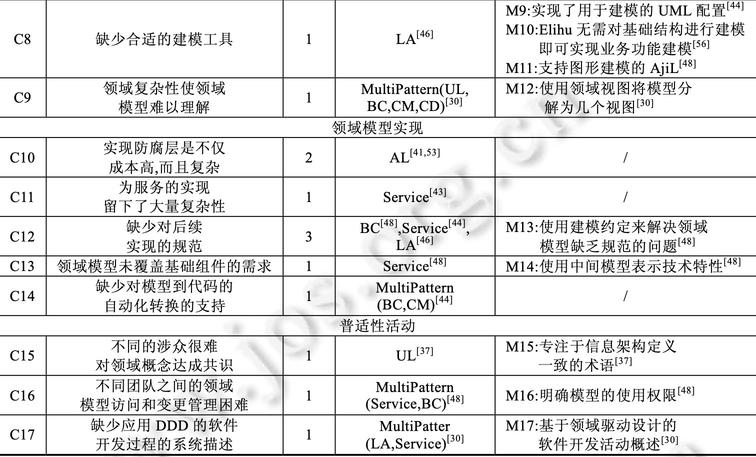
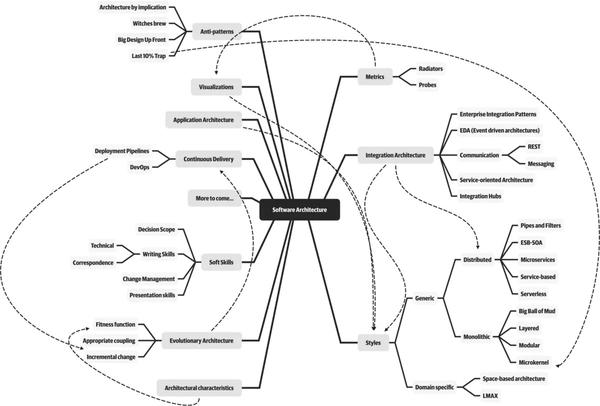
其次学习一些快速阅读的技能
1、指读法:对的,你没看错,用手指指着文字阅读。
2、练习阅读法:刻意练习,比如手指移动更快些,又快又能最大吸收信息
3、积极阅读法:也就是带着问题阅读,或者读完问自己几个问题,这一节主要观点是什么;怎么能记住主要观点;观点拓展以及应用
比如最近有篇转来转去的文章《我在美团的八年》,作者总结了几个原则,第一次看觉得作者讲得真不错,可当在聊天群中再次看到被人转发时,只是想这文章我看过,作者写得不错。但具体内容可能都忘光了。这时不妨回忆下,作者说了哪个原则?最认同哪个?能再加减点别的原则。再阅读比对一下。
而对于质量,是要去学习第一手资料学习原理并且及时更新,尤其像程序员,不然看到的知识可能是错的。
比如,我两年前总结的一篇JVM参数文章:《百万QPS系统JVM参数》,如果你现在看到直接照本全收,估计有些参数有效,有些无效,整体效果你会失望,但也别说我乱写,因为JVM在发展,参数也在更新,而且也是在我当时的系统背景下得出的结论,我的认知也可能是不完整的。
但你掌握了JVM调优原理,并结合最新的JVM规范因地制宜,是没问题的,质量也是有保障的。
再比如你正在看的这篇文章,也是很多手信息后的产物。不是说就不要看了,至少可以激发你的思考,进而去拓展学习。
质量和速度兼并的学习技能是联机学习,我们要做知识的路由器
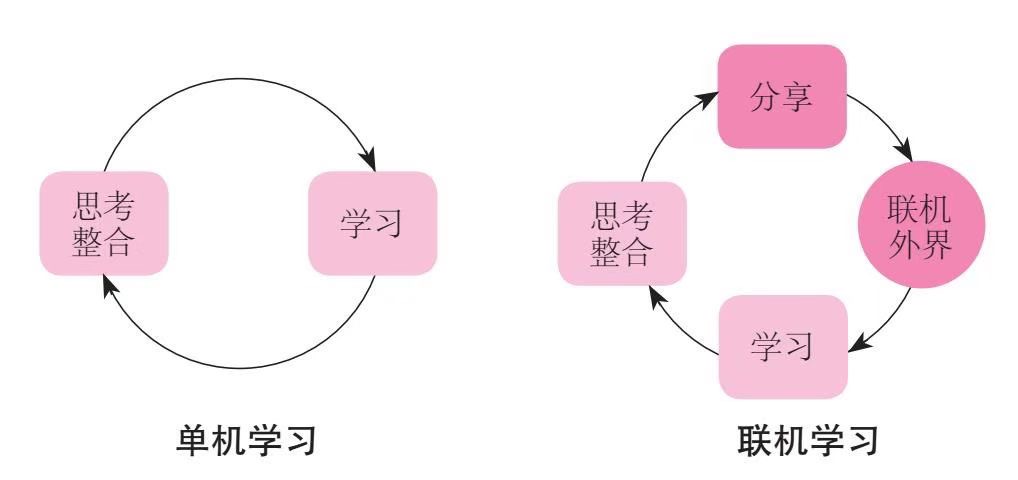
通过交流交换思想,再深入思考,整合归纳。相比个人学习,不管是速度还是质量都会有更大的提升。
为什么要去大厂,不就是能更方便地遇到更牛B的人,快速吸收他们的最新思考成果。
拓展
一味地获取内容和信息,并不一定能达到想要的效果。启发思考才是学习的目的,所以反思是学习真正发生的时候,这样才能去改变我们的行为和思维。
拓展就是思考与反思阶段,只有拓展得好,才会将学到的知道举一反三、触类旁通。也只有这样,后期我们才能应用好知识。
拓展有三种方式:
1、深度拓展
不仅仅理解一个结论就结束,还得挖掘知识从何而来?结论来自何处?一个发现是如何做出来的?结论之前的试验是怎么做的?怎么想起来做的?
一句话,我们要知其然还得知其所以然,多问why,以及how。
2、横向拓展
与知识周围建立联系。
知识不会孤立地存在,与此类似的结论还有哪些?是哪些地方类似?不同的地方在哪里?同一时期还有哪些其他的发现,同一个发现者还有哪些发现,在同一个领域里还有哪些发现?
3、纵向拓展
知识都遵循一定的模式,同样的模式在其他知识中也会出现,能将一个公式与一个自然事件相联系吗?
纵向拓展是有相当难度的。也是最有创造性的学习方式。
比如达芬奇看到鸟在天上飞,他就琢磨鸟在天上飞和鱼在水里游到底有什么共同之处,为什么鱼在水里游那个敏捷的程度明明有水做阻力,但看起来比鸟还快。为什么?后来他就慢慢搞出了流体力学。
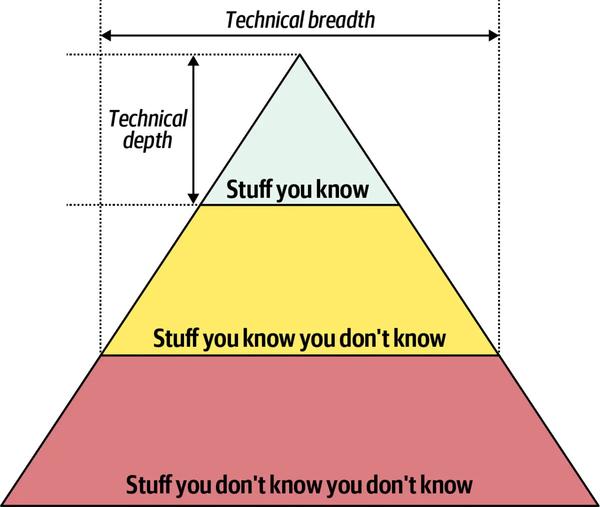
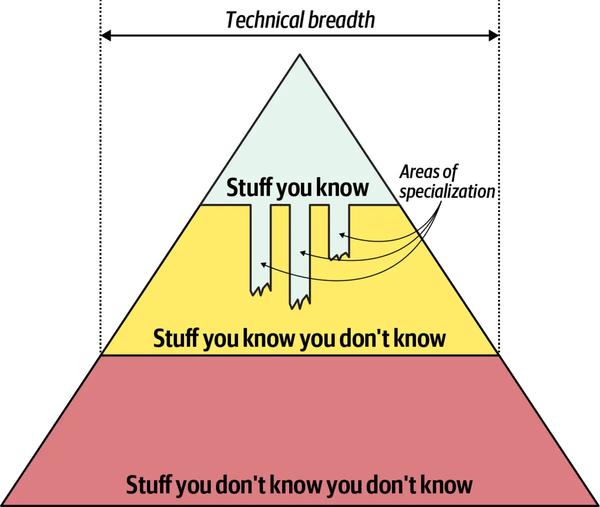
这三种方式似乎有些难以理解,可以类比在《架构与架构师》中提到的架构师技术能力包含的知识深度、宽度、广度。
再如最近我写的《大明湖畔的领域模型》,领域模型因OOA被提出,让我们寻找现实中的概念类,万物皆对象,映射到具体软件实现类。而同时期Martin Fowler也提出了Domain Model,却是对OO升华,要充血模型,不要贫血模型。再到现如今大家热议DDD中的领域模型,Eric推崇的分析模型与实现模型统一融合。
一个概念被各方位拓展后,原始的软件方法论被突破,各种全新软件方法论被创造。
高效学习
赚钱只能赚到认知范围内的钱,不然凭运气赚取的钱也会被实力亏掉;同样,学习也是如此。只是知道如何学习,无法内化这些认知,学习行为的效率依然低下。
如何能高效学习,我们需要再一次反思自己对学习的元认知。
错觉
我们的元认知非常容易出现偏差,常会产生两个误区:
1、不知道自己学习中的薄弱之处,不知道要在哪里花更多精力才能提高自己的知识水平
2、爱使用那些会让自己错误地认为掌握了知识的学习方法,也就是拼命记笔记、拼命画下划线、拼命地用荧光笔、拼命地反复阅读
怎么解决这两个误区?巩固与检索。
学习越轻松,效果越不好,看来起来非常勤奋,不停地背书,一遍一遍地背,拿笔一遍一遍地画,甚至是一遍一遍地抄,看起来很勤奋耗费大量的时间,但他的学习过程是很轻松的,没有做到有挑战的事情。
通过检索、考试,不断地挑战来巩固记忆。
比如要跳槽了,怎么去准备面试呢?拿出浩瀚如烟的资料去慢慢复习吗?或者找一堆面试题来刷吗?
这些都很低效,不如自己玩一把角色扮演,扮演下面试官,给自己出一份面试题,出题需要检索知识点,解题也需要挑战记忆。
再按知识模块与各种资料比对自己的知识掌握度,查漏补缺,事半功倍。
问题树
认知心理学认为,有三个前提要求时,学习效率最高:
1、有目标导向,俗称带着问题学习
2、有即时反馈,为什么游戏好玩?
3、最近发展区,当前水平与通过学习获得的潜力之间的差异叫最近发展区
那么怎么样的学习方式才会同时拥有这几个前提呢?使用问题树的思维方式替代知识树的思维方式。
知识树的思路,是典型的专业知识细分的学习路径。工业时代分工高度稳定,每个领域都相对独立、发展缓慢,一个人有机会学完一个细分领域的所有知识。沿着一棵长成的大树向上爬,这种学习路径效率最高。
但在一个高度变化、多领域跨界的时代,完成任何任务都需要调取多领域的知识,全部靠自己学习显然来不及。
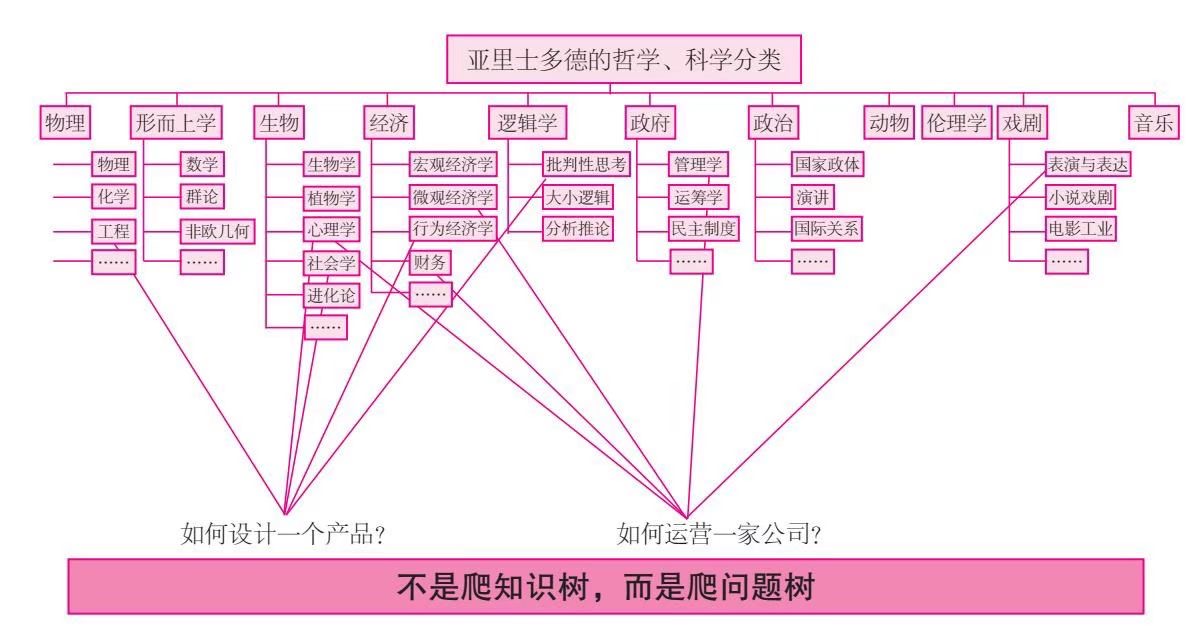
当我们想学习某一知识时,常列个计划,搜集资料,罗列书单、阅读清单,可涉及面很广,这样难免有很大的随机时,书单虽全虽好,最后没有动力去读,读了也没有实践的动力。
而以问题为切入点,问题使目标更清晰,不会在知识树里迷路;动力也更强,一个问题解锁后,会带来更多、更大、更有趣的问题。
时代是水流,答案是河岸,而问题是船只。
在水流不快的时代,可以在河岸上慢慢走,也许跟得上水流;但在知识爆炸、洪流时代,只有登上船只,才能保持和时代同步。守在岸上,只能被远远抛下,望洋兴叹。
不要学习
相对现如今提出的终身学习者,是不是有些反人类。
不要学习,指的是在没有明确自己究竟想达到什么目的,就去不停地“学习”,实在是对宝贵时间资源的浪费。而且学习得多,未必收获得就好。
打个比方,学习就好比整个食物经过咀嚼、消化、吸收的过程,它不是表面看起来“吃”的动作。人们不可能永远吃个不停,所以学习行为不是越多越好。
学习需要挑选吃的食物(获取信息)、咀嚼(明白阶段)、消化(理解阶段)、吸收(应用阶段)。
犹如ThoughtWorks中国区CTO徐昊在他的专栏《业务建模》中所说,技术没有反哺过我的生活,反而我的人生给养了在技术上的洞见。吃喝玩乐并不耽误事,因为学习是一种状态(being),而不是一种行为(doing)。在学习的状态中,吃喝玩乐都可以让我成为更好的程序员。
找到自己的目标,不要人云亦云,刻意宣传终身学习更多时刻是商家制造的焦虑感收缴人们的智商税。
总结
世人都知道认知能力重要性时,我们更需要去认知一下如何更好地获得认知的能力。
“学习”本身不是一件容易的事,在我们长期实践“学习”的空隙,需要对“学习”保留一份反思,学习学习,加深对学习元认知的认识。
不需要刻意终身学习,更不必因终身学习而焦虑,它就是我们的血液。是这个时代赋予我们的第二呼吸。
学习行为像吃饭,学习状态像呼吸。不要为了学习而学习,贪图勤奋的假象带来的快感。
回到篇首,提到我的切身经历,问题的本质是认知效率:认知收益与时间精力之比,牛人真正的秘诀是在最精华的资源上,以高很多倍的认知资源来学习。要事第一。
当然在认知水平不够时,也不要吝啬自己的时间。毕竟我们已经与牛人有了差距,花功夫才能得到真功夫。
最后的最后,如果你对学习主题也感兴趣,可以延伸阅读《刻意练习》、《认知天性》、《如何高效学习》、《人是如何学习的》、《卡片笔记法》、《跃迁》。