DDD这个主题已经写了好多篇文章了,结合最近的思考实践是时候总结一下,对于战略部分有点宏大,现在都是在微服务划分中起着重要作用,暂且总结战术部分
DDD意义 每种理论的诞生都是站在前人的基础之上,总得要解决一些痛点;DDD自己标榜的是解决复杂软件系统,对于复杂怎么理解,至少在DDD本身理论中并没有给出定义,所以是否需要使用DDD并没有规定,事务脚本式编程也有用武之地,DDD也不是放之四海皆准,也就是常说的没有银弹
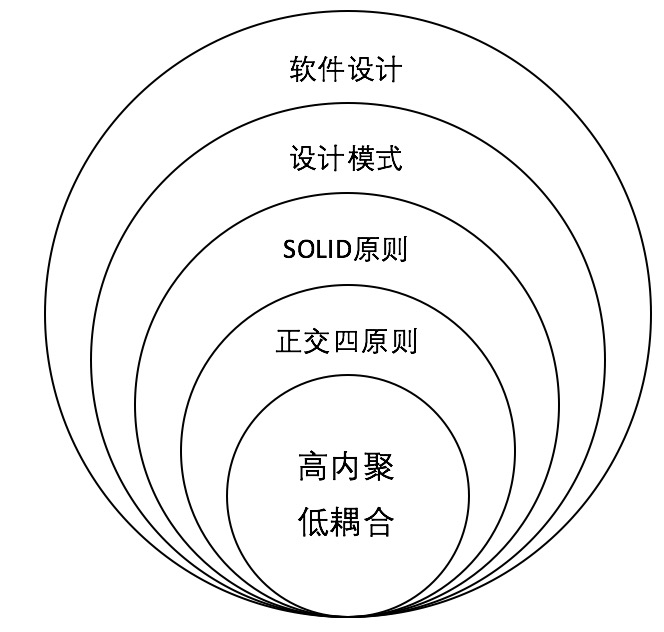
但重点是每种方法论都得落地,必须要以降低代码复杂度为目标,因此对于“统一语言”、“界限上下文”对于一线码农有点远,那战术绝对是一把利剑
回顾一下,在没有深入DDD之前,基本上就是事务脚本式编程,当然还会重构,怎么重构呢?基本也是大方法变小方法+公共方法
随着业务需求越来越多,代码自然伴随增长,就算重构常相伴,后期再去维护时也是力不从心,要么小方法太多,要么方法太大,老人也只能匍匐前行,新人是看得懂语法却不知道语义,这也是程序员常面对的挑战,不是在编写代码,而是在摸索业务领域知识
那怎么办呢?有没有其它模式,把代码写漂亮,降低代码复杂度,真正的可扩展、可维护、可测试呢?
很多人会说面向对象啊,可谁没在使用面向对象语言呢?可又怎样。事实是不能简单的使用面向对象语言,得要有面向对象思维,还得再加上一些原则,如SOLID
但虽然有了OOP,SOLID,设计模式,还是逃不脱事务脚本编程,这里面有客观原因,业务系统太简单了,OO化不值得,不能有了锤子哪里都是钉子;主观原因,长时间的事务脚本思维实践,留在了舒适区,缺乏跳出的勇气
DDD战术部分给了基于面向对象更向前一步的范式,这就是它的意义
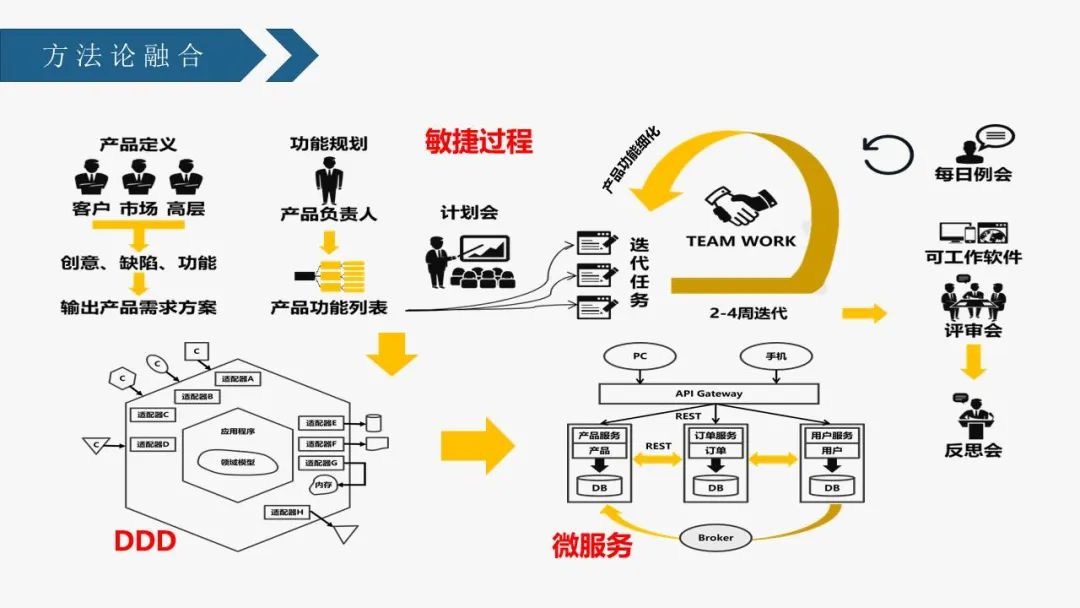
在实践DDD过程中,我也一直在寻找基于完美理论的落地方案,追求心中的那个DDD,常常在理论与实践的落差间挣扎,在此过程中掌握了一些套路,心中也释然了对理论的追求,最近关注到业务架构,看到一张PPT,更是减少了心中的偏执,这份偏执也是一种对银弹的追求,虽然嘴大多数时候说没有,但身体很诚信
在这张方法融合论里面,DDD只是一小块,为什么要心中充满DDD呢,不都是进阶路上的垫脚石。想起牛人的话,站到更高的维度让问题不再是问题才是最牛的解决问题之道
事务脚本式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 @RestController @RequestMapping("/") public class CheckoutController { @Resource private ItemService itemService; @Resource private InventoryService inventoryService; @Resource private OrderRepository orderRepository; @PostMapping("checkout") public Result<OrderDO> checkout(Long itemId, Integer quantity) { // 1) Session管理 Long userId = SessionUtils.getLoggedInUserId(); if (userId <= 0) { return Result.fail("Not Logged In"); } // 2)参数校验 if (itemId <= 0 || quantity <= 0 || quantity >= 1000) { return Result.fail("Invalid Args"); } // 3)外部数据补全 ItemDO item = itemService.getItem(itemId); if (item == null) { return Result.fail("Item Not Found"); } // 4)调用外部服务 boolean withholdSuccess = inventoryService.withhold(itemId, quantity); if (!withholdSuccess) { return Result.fail("Inventory not enough"); } // 5)领域计算 Long cost = item.getPriceInCents() * quantity; // 6)领域对象操作 OrderDO order = new OrderDO(); order.setItemId(itemId); order.setBuyerId(userId); order.setSellerId(item.getSellerId()); order.setCount(quantity); order.setTotalCost(cost); // 7)数据持久化 orderRepository.createOrder(order); // 8)返回 return Result.success(order); } }
这是经典式编程,入参校验、获取数据、逻辑计算、数据存储、返回结果,每一个use case基本都是这样处理的,套路就是取数据、计算数据、存数据;当然,有时我们常把中间的一块放到service中。随着use case越来越多,会把一些重复代码提取出来,比如util,或者公共的service method,但这些仍然是一堆代码,可读性、可理解性还是很差,这两个很差,那可维护性就没法保证,更不用提可扩展性,为什么?因为这些代码缺少了灵魂。何为灵魂,业务模型。
对于事务脚本式也有模型,单只有数据模型,而没有对象模型。模型是对业务的表达,没有了业务表达能力的代码,人怎么能读懂
而DDD在领域模型方式就有很强的表达能力,当然在编码时也不会以数据流向为指导。先写Domain层的业务逻辑,然后再写Application层的组件编排,最后才写每个外部依赖的具体实现,这就是Domain-Driven Design,其实这类似于TDD,谁驱动谁就得先行
反DDD 任何事物都是过犹不及,如文章开头所述,没有银弹,千万别因为DDD的火热而一股脑全身心投入DDD,不管场景是否适合,都要DDD;犹如设计模式,后面出现了大量的反模式。
错误的抽象比没有抽象伤害力更大
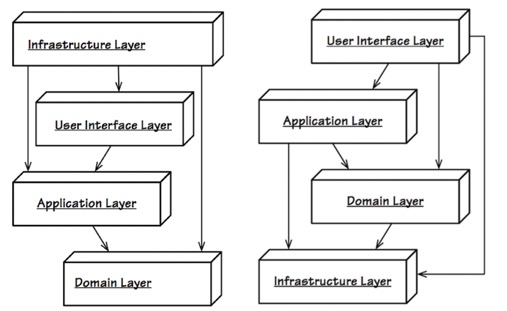
DDD分层
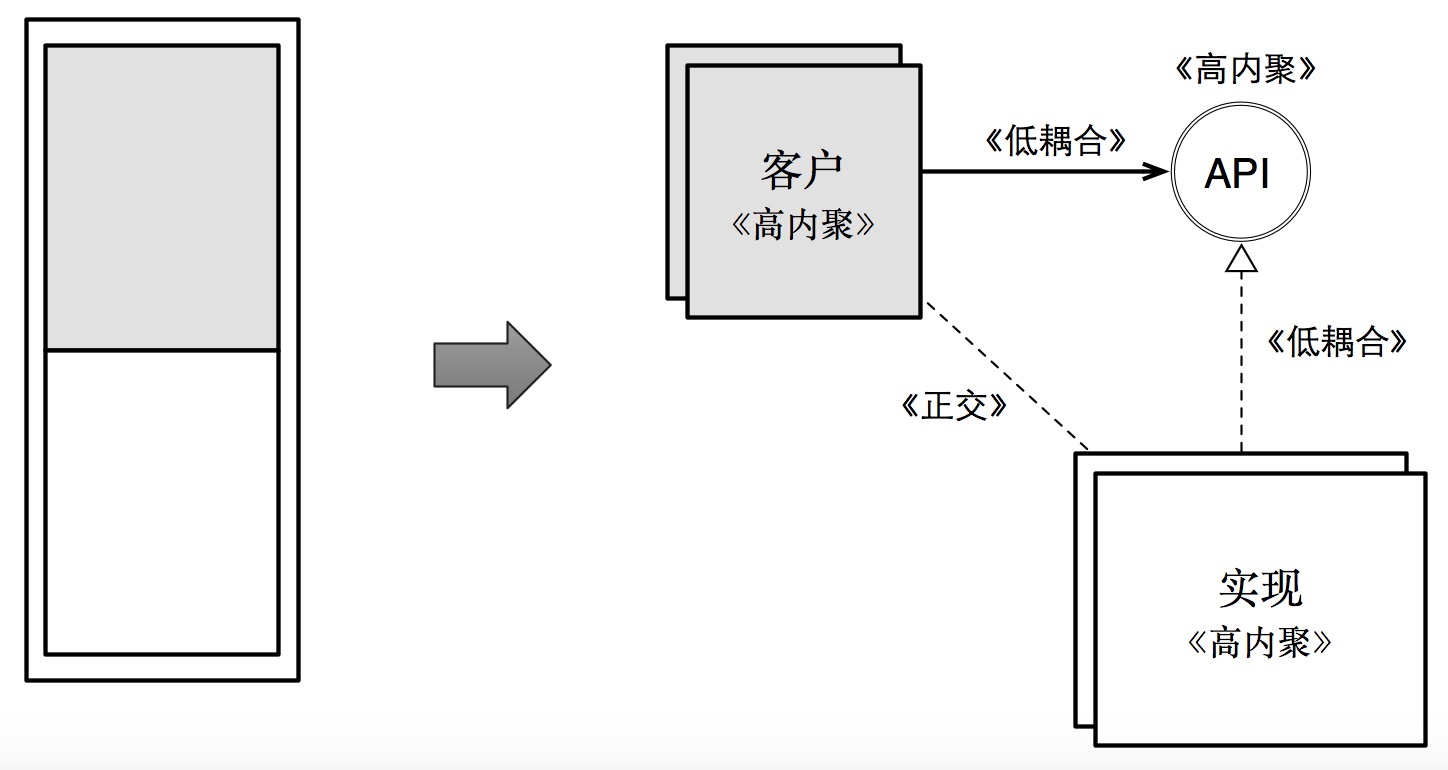
Interface层 对于这一层的作用就是接受外部请求,主要是HTTP和RPC,那也就依赖于具体的使用技术,是spring mvc、还是dubble
在DDD正统分层里面是有这一层的,但实践时,像我们的controller却有好几种归类
一、User Interface归属于大前端,不在后端服务,后端服务从application层开始
二、正统理论,就是放在interface层
三、controller毕竟是基于具体框架实现,在六边形架构中就是是个 adapter,归于 Infrastructure 层
对于以上三种归类,都有实践,都可以,但不管怎么归属,他的属性依然是 Interface
对于Interface落地时指导方针:
统一返回值,interface是对外,这样可以统一风格,降低外部认知成本
全局异常拦截,通过aop拦截,对外形成良好提示,也防止内部异常外溢,减少异常栈序列化开销
日志,打印调用日志,用于统计或问题定位
遵循ISP,SRP原则,独立业务独立接口,职责清晰,轻便应对需求变更,也方便服务治理,不用担心接口的逻辑重复,知识沉淀放在application层,interface只是协议,要薄,厚度体现在application层
1 2 3 4 5 6 7 8 9 10 11 12 @Data public class Result<T> { /** 错误码 */ private Integer code; /** 提示信息 */ private String msg; /** 具体的内容 */ private T data; }
Application层 应用层主要作用就是编排业务,只负责业务流程串联,不负责业务逻辑
application层其实是有固定套路的,在之前的文章有过阐述,大致流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 application service method(Command command) { //参数检验 check(command); Aggregate aggregate = repository.findAggregate(command); //复杂的需要domain service aggregate.operate(command); repository.saveOrUpdate(aggregate); publish(event); return DTOAssembler.to(aggregate); }
业务流程 VS 业务规则 对于这两者怎么区分,也就是application service 与 domain service 的区分,最简单的方式:业务规则是有if/else的,业务流程没有
现在都是防御性编程,在check(command)部分,会做很多的precondition
比如转帐业务中,对于余额的前提判断:
1 2 3 4 5 6 public void preDebit(Account account, double amount) { double newBalance = account.balance() - amount; if (newBalance < 0) { throw new DebitException("Insufficient funds"); } }
这算是业务规则还是业务流程呢?这一段代码可以算是precondition,但也是业务规则的一部分,颇有争议,但没有正确答案,只是看你代码是否有复用性,目前我个人倾向于放在业务规则中,也就是domain层
厚与薄 常人讲,application service是很薄的一层,要把domain做厚,但从最开始的示例,发现其实application service特别多,而domain只有一行代码,这不是application厚了,domain薄了
对于薄与厚不再于代码的多与少,application层不是厚,而是编排多而已,逻辑很简单,一般厚的domain大多都是有比较复杂的业务逻辑,比如大量的分支条件。一个例子就是游戏里的伤害计算逻辑。另一种厚一点的就是Entity有比较复杂的状态机,比如订单
出入参数 先讲一个代码示例:
从controller接受到请求,传入application service中,需要做一层转换,controller层
示例一段创建目录功能的对象转换:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Data public class DirectoryDto extends BaseRequest { private long id; @NotBlank @ApiModelProperty("目录编号") private String directoryNo; @NotBlank @ApiModelProperty("目录名称") private String directoryName; private String directoryOrder; private String use; private Long parentId; } com.jjk.application.dto.directory.DirectoryDto to(com.jjk.controller.dto.DirectoryDto directoryDto);
创建目录,入参只需要directoryNo,directoryName,为了少写代码,把编辑目录(directoryDto中带了id属性),response(directoryDto包含了目录所有信息)都揉合在一个dto中了
这样就会有几个问题:
违背SRP,创建与编辑两个业务功能却混杂在了一个dto中
相对SRP,更大的问题是业务语义不明确,DDD中一个优势就是要业务语义显示化
怎么解决呢?
引入CQRS元素:
Command指令:指调用方明确想让系统操作的指令,其预期是对一个系统有影响,也就是写操作。通常来讲指令需要有一个明确的返回值(如同步的操作结果,或异步的指令已经被接受)
Query查询:指调用方明确想查询的东西,包括查询参数、过滤、分页等条件,其预期是对一个系统的数据完全不影响的,也就是只读操作
这样把创建与编辑拆分,CreateDirectoryCommand、EditDirectoryCommand,这样有了明确的”意图“,业务语义也相当明显;其次就是这些入参的正确性,之前事务脚本代码中大量的非业务代码混杂在业务代码中,违背SRP;可以利用java标准JSR303或JSR380的Bean Validation来前置这个校验逻辑,或者使用Domain Primitive,既能保证意图的正确性,又能让application service代码清爽
而出参,则使用DTO,如果有异常情况则直接抛出异常,如果不需要特殊处理,由interface层兜底处理
对于异常设计,可根据具体情况处理,整体由业务异常BusinessException派生,想细化可以派生出DirectoryNameExistException,让interface来定制exception message,若无需定制使用默认message
Domain层 domain层是业务规则的集合,application service编排业务,domain service编排领域;
domain体现在业务语义显现化,不仅仅是一堆代码,代码即文档、代码即业务;要达到高内聚就得充分发挥domain层的优势,domain层不单单是domain service,还有entity、vo、aggregate
domain层是最最需要拥抱变化的一层,为什么?domain代表了业务规则,业务规则来自于需求,日常开发中,需求是经常变化的
我们需要逆向思维,以往我们去封装第三方服务,解耦外部依赖,大多数时候是考虑外部的变化不要影响自身,而现实中,更多的变化来自内部:需求变了,所以我们应该更多关注一个业务架构的目标:独立性,不因外部变化而变化,更要不因自身变化影响外部服务的适应性
在《DDD之Repository》中指出Domain Service是业务规则的集合,不是业务流程,所以Domain Service不应该有需要调用到Repo的地方。如果需要从另一个地方拿数据,最好作为入参,而不是在内部调用。DomainService需要是无状态的,加了Repo就有状态了。domainService是规则引擎,appService才是流程引擎。Repo跟规则无关
也就是domain层应该是一个纯内存操作,不依赖外部任何服务,这样提高了domain层的可测试性,拥抱变化的底气也来自于完整的UT,而application层UT全部得mock
Infrastructure层 Infrastructure层是基础实施层,为其他层提供通用的技术能力:业务平台,编程框架,持久化机制,消息机制,第三方库的封装,通用算法,等等
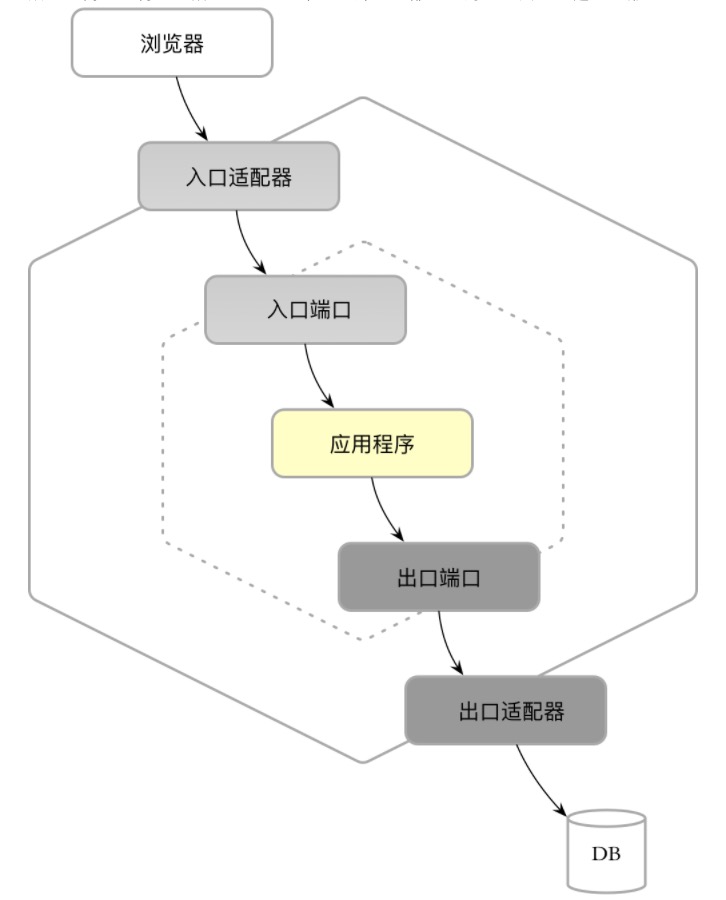
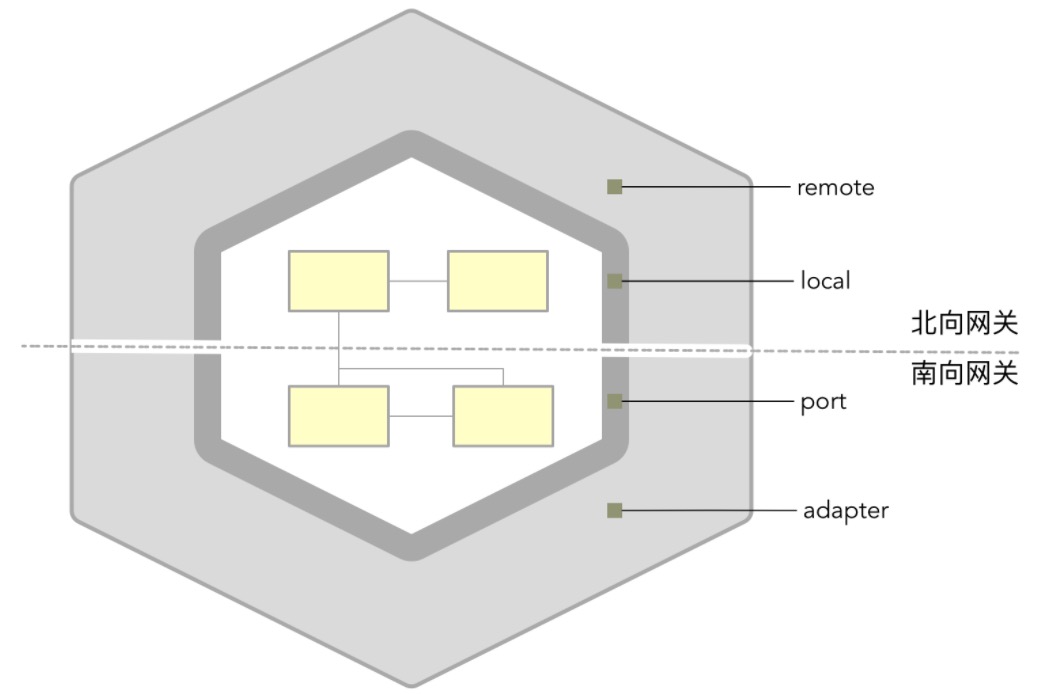
Martin Fowler将“封装访问外部系统或资源行为的对象”定义为网关(Gateway),在限界上下文的内部架构中,它代表了领域层与外部环境之间交互的出入口,即:
gateway = port + adapter
这一点契合了六边形架构
在实际落地时,碰到的问题就是DIP问题,Repository在DDD中是在Domain层,但具体实现,如DB具体实现是在Infrastructure层,这也是符合整洁架构,但DDD限界上下文可能不仅限于访问数据库,还可能访问同样属于外部设备的文件、网络与消息队列。为了隔离领域模型与外部设备,同样需要为它们定义抽象的出口端口,这些出口端口该放在哪里呢?如果依然放在领域层,就很难自圆其说。例如,出口端口EventPublisher支持将事件消息发布到消息队列,要将这样的接口放在领域层,就显得不伦不类了。倘若不放在位于内部核心的领域层,就只能放在领域层外部,这又违背了整洁架构思想
这个问题张逸老师提出了菱形架构,后面的章节中再论述
再次比较interface与infrastructure,在前面讲述到controller的归属,其实就隐含了interface与infra的关联,这两者都与具体框架或外部实现相关,在六边形架构中,都归属为port与adapter
我一般的理解:从外部收到的,属于interface层,比如RPC接口、HTTP接口、消息里面的消费者、定时任务等,这些需要转化为Command、Query,然后给到App层。
App主动能去调用到的,比如DB、Message的Publisher、缓存、文件、搜索这些,属于infra层
所以消息相关代码可能会同时存在2层里。这个主要还是看信息的流转方式,都是从interface -> Application -> infra
整洁架构
一个好的架构应该需要实现以下几个目标:
独立于框架:架构不应该依赖某个外部的库或框架,不应该被框架的结构所束缚
独立于UI:前台展示的样式可能会随时发生变化
独立于底层数据源:无论使用什么数据库,软件架构不应该因不同的底层数据储存方式而产生巨大改变
独立于外部依赖:无论外部依赖如何变更、升级,业务的核心逻辑不应该随之而大幅变化
可测试:无论外部依赖什么样的数据库、硬件、UI或服务,业务的逻辑应该都能够快速被验证正确性
这几项目标,也对应我们对domain的要求:独立性和可测试;我们的依赖方向必须是由外向内
DIP与Maven 要想实现整洁架构目标,那必须遵循面向接口编程,达到DIP
1 2 3 4 5 6 7 8 <modules> <module>assist-controller</module> <module>assist-application</module> <module>assist-domain</module> <module>assist-infrastructure</module> <module>assist-common</module> <module>starter</module> </modules>
在使用maven构建项目时,整个依赖关系是:starter -> assist-controller -> assist-application -> assist-domain -> assit-infrastructure
domain层并不是中心层,为什么呢?为什么domain不在最中心?
主要是存在一个循环依赖问题:repository接口在domain层,但现实在infra层,可从maven module依赖讲,domain又是依赖infra模块,domain依赖infra的原由是因为前文所述
DDD限界上下文可能不仅限于访问数据库,还可能访问同样属于外部设备的文件、网络与消息队列。为了隔离领域模型与外部设备,同样需要为它们定义抽象的出口端口,这些出口端口该放在哪里呢
按此划分module,这些出口端口都放在了infra层,当domain需要外部服务时,不得不依赖infra module
对此问题的困惑持续很久,一直认为菱形架构是个好的解决方案,但今年跟阿里大佬的交流中,又得到些新的启发
EventPublisher接口就是放在Domain层,只不过namespace不是xxx.domain,而是xxx.messaging之类的
像repsoitory是在Domain层,但是从理论上是infra层,混淆了两个概念一个是maven module怎么搞,一个是什么是Domain层
以namespace区分后,得到的依赖关系就是DIP后的DDD
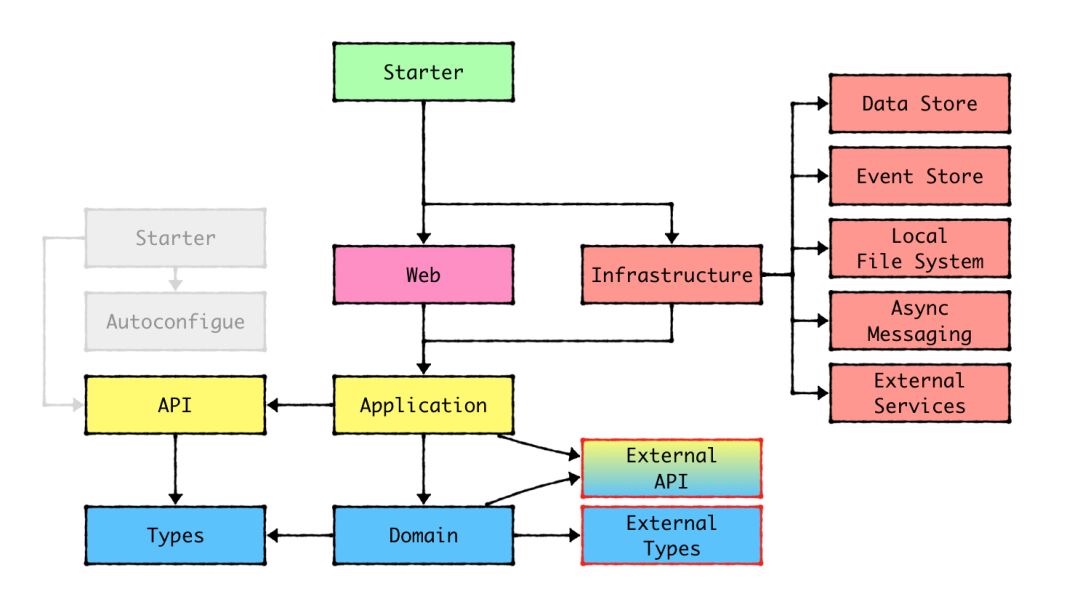
菱形架构 上文中多次提到菱形架构,这是张逸老师发明的,去年项目中,我一直使用此架构
一是解决了上文中的DIP问题,二是整个架构结构清晰职责明确
简单概述一下:
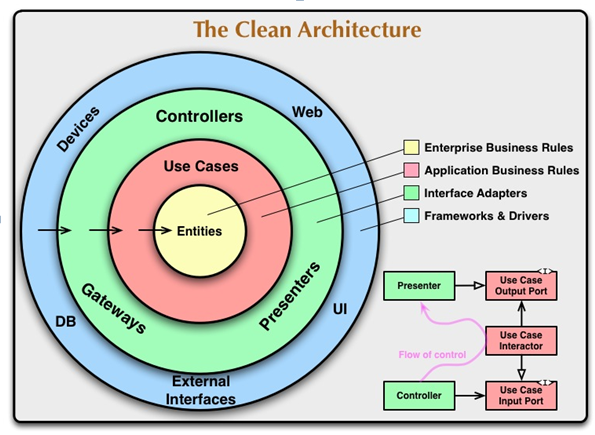
把六边形架构与分层架构整合时,发现六边形架构与领域驱动设计的分层架构存在设计概念上的冲突
出口端口用于抽象领域模型对外部环境的访问,位于领域六边形的边线之上。根据分层架构的定义,领域六边形的内部属于领域层,介于领域六边形与应用六边形的中间区域属于基础设施层,那么,位于六边形边线之上的出口端口就应该既不属于领域层,又不属于基础设施层。它的职责与属于应用层的入口端口也不同,因为应用层的应用服务是对外部请求的封装,相当于是一个业务用例的外观。
根据六边形架构的协作原则,领域模型若要访问外部设备,需要调用出口端口。依据整洁架构遵循的“稳定依赖原则”,领域层不能依赖于外层。因此,出口端口只能放在领域层。事实上,领域驱动设计也是如此要求的,它在领域模型中定义了资源库(Repository),用于管理聚合的生命周期,同时,它也将作为抽象的访问外部数据库的出口端口。
将资源库放在领域层确有论据佐证,毕竟,在抹掉数据库技术的实现细节后,资源库的接口方法就是对聚合领域模型对象的管理,包括查询、修改、增加与删除行为,这些行为也可视为领域逻辑的一部分。
然而,限界上下文可能不仅限于访问数据库,还可能访问同样属于外部设备的文件、网络与消息队列。为了隔离领域模型与外部设备,同样需要为它们定义抽象的出口端口,这些出口端口该放在哪里呢?如果依然放在领域层,就很难自圆其说。例如,出口端口EventPublisher支持将事件消息发布到消息队列,要将这样的接口放在领域层,就显得不伦不类了。倘若不放在位于内部核心的领域层,就只能放在领域层外部,这又违背了整洁架构思想。
如果我们将六边形架构看作是一个对称的架构,以领域为轴心,入口适配器和入口端口就应该与出口适配器和出口端口是对称的;同时,适配器又需和端口相对应,如此方可保证架构的松耦合。
1 2 3 4 5 6 <modules> <module>assist-ohs</module> <module>assist-service</module> <module>assist-acl</module> <module>starter</module> </modules>
这有点类似《DDD之形》中提到的端口模式,把资源库Repository从domain层转移到端口层和其它端口元素统一管理,原来的四层架构变成了三层架构,对repository的位置从物理与逻辑上一致,相当于扩大了ACL范围
这个架构结构清晰,算是六边形架构与分层架构的融合体,至于怎么选择看个人喜爱
Event 相对Event Source,这儿更关注一下event的发起,是不是需要区分应用事件和领域事件
根据application的套路,会publish event,那在domain service中要不要publish event呢?
Domain Event更多是领域内的事件,所以应该域内处理,甚至不需要是异步的。Application层去调用消息中间件发消息,或调用三方服务,这个是跨域的。
从目前的实践来看,直接抛Domain Event做跨域处理这件事,不是很成熟,特别是容易把Domain层的边界捅破,带来完全不可控的副作用
所以结合application,除了Command、Query入参,还需要Event入参,处理事件
总结 本文主要是按DDD分层,介绍各层落地时的具体措施,以及各层相应的规范,引入CQRS使代码语义显现化,通过DIP达到整洁架构的目标
对于domain层,有个重要的aggregate,涉及模型的构建,千人千模,但domain层的落地是一样的
在业务代码中有几个比较核心的东西:抽象领域对象合并简单单实体逻辑,将多实体复杂业务规则放到DomainService里、封装CRUD为Repository,通过App串联业务流程,通过interface提供对外接口,或者接收外部消息
其实不论使用DDD,还是事务脚本,合适的才是最好的,任何方法论都得以降低代码复杂度为目的