zk相关文章已经有了三篇
《zookeeper-paxos》、
《zookeeper知识结构》、
《zookeeper知识结构2-zab协议》
但都没有到具体到应用,此篇弥补一下
talk is cheap,show me the code
client
如何使用zk
除了zk提供原生客户端,还有能过编程方式
zkcli
zkcli原生操作指令比较简单
1 | zkcli 连接默认zookeeper服务器 |
ZkClient VS Curator
这两个常用的开源组件
相对zkclient,Curator已经成为Apache的顶级项目,不仅解决了非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等,还提供了Zookeeper各种应用场景(Recipe,如共享锁服务、Master选举机制和分布式计算器等)的抽象封装
所以推荐使用curator
应用
主要介绍两种常见情景,一是分布式锁,二是master选举
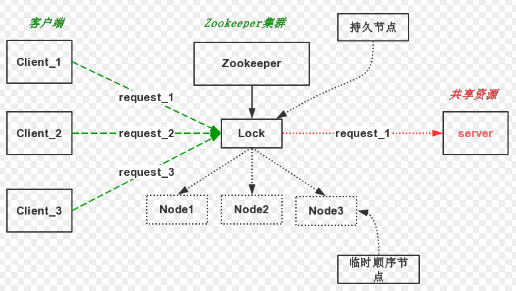
分布式锁
为什么zk能实现分布式锁?
像redis原理是通过全局key是否存,而zk则是通过其特定的数据结构来实现:利用节点名称的唯一性
ZooKeeper抽象出来的节点结构是一个和unix文件系统类似的小型的树状的目录结构。ZooKeeper机制规定:同一个目录下只能有一个唯一的文件名。例如:我们在Zookeeper目录/jjk目录下创建,两个客户端创建一个名为Lock节点,只有一个能够成功
思路一:持久节点
利用名称唯一性,加锁操作时,只需要所有客户端一起创建/lock节点,只有一个创建成功,成功者获得锁。解锁时,只需删除/lock节点,其余客户端再次进入竞争创建节点,直到所有客户端都获得锁
代码片段
尝试加锁1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* 尝试加锁,直接创建节点,如果节点创建失败,说明加锁失败
* @param lockName
* @return
*/
public boolean tryLock(String lockName) {
try {
//创建节点
String path = cf.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath(getLockPath(lockName), lockName.getBytes());
logger.info(Thread.currentThread().getName()+ "try lock success ,path:"+path+" tid:"+Thread.currentThread().getName());
return true;
}catch (KeeperException.NodeExistsException e) {
logger.info("try lock fail,"+" tid:"+Thread.currentThread().getName());
}catch (Exception ex) {
ex.printStackTrace();
}
return false;
}
尝试加锁失败后,阻塞等待1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41/**
* 尝试加锁失败后,阻塞等待
* @param lockName
* @throws Exception
*/
public void waitForLock(String lockName) throws Exception {
//监听子节点
PathChildrenCache pathChildrenCache = new PathChildrenCache(cf, LOCK_PATH, false);
pathChildrenCache.start(PathChildrenCache.StartMode.BUILD_INITIAL_CACHE);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
switch (event.getType()) {
case CHILD_REMOVED:
logger.info("path:" + event.getData().getPath() + " has removed,start to lock:{}",Thread.currentThread().getName());
countDownLatch.countDown();
break;
default:
//logger.info(" has changeed,{},start to lock:{}",event.getType(),Thread.currentThread().getName());
break;
}
}
});
boolean hasLock = false;
while(!hasLock) {
Stat stat = cf.checkExists().forPath(getLockPath(lockName));
//节点存在,此处与unlock非原子操作,如果在checkExists返回true时刻,成功unlock,那此端无限等待
if (stat == null) {
logger.info("waitForLock not exists:{}", Thread.currentThread().getName());
hasLock = tryLock(lockName);
if(hasLock) {
logger.info("waitForLock get lock :{}", Thread.currentThread().getName());
break;
}
} else {
logger.info("waitForLock exists:{}", Thread.currentThread().getName());
countDownLatch.await();
}
}
}
解锁1
2
3
4
5
6public boolean unlock(String lockName) throws Exception {
logger.info("start unlock:" + lockName + " tid:" + Thread.currentThread().getName());
cf.delete().forPath(getLockPath(lockName));
logger.info("end unlock:" + lockName + " tid:" + Thread.currentThread().getName());
return true;
}
这个方案比较简单,但会出现两个问题:
- “惊群效应”,所有客户端都是监听这个节点变化,当一端释放锁时,别的端都会抢占
- 如果加锁成功的client突然崩溃,那么锁无法正常释放,全局进入死锁状态
思路二:临时有序节点
为了应对上面的问题,可以使用临时有序节点:EPHEMERAL_SEQUENTIAL,之前的篇章中说明了临时节点特点,在client与zk断开连接时,临时节点会自动删除
加锁算法:
- 客户端调用create()方法创建名为“/lock”的节点,需要注意的是,这里节点的创建类型需要设置为EPHEMERAL_SEQUENTIAL
- 客户端调用getChildren(“lock”)方法来获取所有已经创建的子节点,同时在这个节点上注册上子节点变更通知的Watcher
- 客户端获取到所有子节点path之后,如果发现自己在步骤1中创建的节点是所有节点中序号最小的,那么就认为这个客户端获得了锁
- 如果在步骤3中发现自己并非是所有子节点中最小的,说明自己还没有获取到锁,就开始等待,直到下次子节点变更通知的时候,再进行子节点的获取,判断是否获取锁
解锁算法:
- 删除自己创建的那个子节点
代码片段
尝试加锁失败后,阻塞等待1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public void waitForLock(String lockName) throws Exception {
logger.info("waitForLock {}:{}",beforeNode, Thread.currentThread().getName());
boolean hasLock = false;
while(!hasLock) {
//是不是最小节点
boolean isMin = isMinNode();
if (isMin) {//是 则成功获取锁
logger.info("waitForLock getLock:{}", Thread.currentThread().getName());
break;
} else {
try {
cf.getData().usingWatcher(new Watcher() {
@Override
public void process(WatchedEvent event) {
switch (event.getType()) {
case NodeDeleted:
logger.info("path:" + event.getPath() + " has removed,before:{},start to lock:{}", beforeNode, Thread.currentThread().getName());
countDownLatch.countDown();
break;
}
}
}).forPath(beforeNode);
logger.info("waitForLock waiting:{}", Thread.currentThread().getName());
countDownLatch.await();
logger.info("开始抢占:{},{}", Thread.currentThread().getName(), currentNode);
}catch (KeeperException.NoNodeException e){
logger.info("waitForLock has delete:{},{}",beforeNode, Thread.currentThread().getName());
}
}
}
}
这个方案解决了思路一中的问题
- 只监听当前节点的上一个节点,这样就解决了“惊群”现象
- 临时节点,当连接断开后,就会自动删除,不会出现过期时间问题
完美了吗?
再回看《剖析分布式锁》。zk实现方式完美了吗?
显然示例中没有达到好锁的标准,更完善的实现可以看看curator中的InterProcessLock
单机
此锁高可用了吗?对比一下Redis,哪种方案更完美?
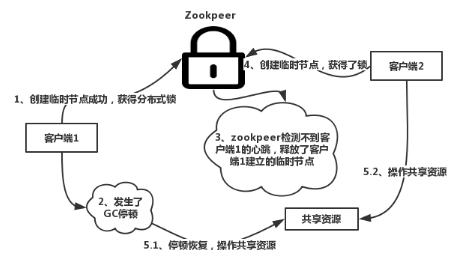
客户端1发生GC停顿的时候,zookeeper检测不到心跳,也是有可能出现多个客户端同时操作共享资源的情形
redis的最新set指令,zk的临时节点两个性质都是一样的,解决了因过期时间问题引起的死锁
有了“续命丸”方案,在单机情况下,redis更完美些,至少不会出现zk临时节点因session超时提前删除问题
集群
在集群下呢? 线上环境,为了高可用不大会使用单点
如redis的cluster,哨兵模式;但由于Redis的主从复制(replication)是异步的,这可能会出现在数据同步过程中,master宕机,slave来不及同步数据就被选为master,从而数据丢失
- 客户端1从Master获取了锁
- Master宕机了,存储锁的key还没有来得及同步到Slave上
- Slave升级为Master
- 客户端2从新的Master获取到了对应同一个资源的锁
RedLock算法
为了应对这个情形, redis的作者antirez提出了RedLock算法,步骤如下(该流程出自官方文档),假设我们有N个master节点(官方文档里将N设置成5,其实大等于3就行)
- 获取当前时间(单位是毫秒)
- 轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点
- 客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁(在这里是3个),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了
- 如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间
- 如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁
缺陷
比如一下场景,两个客户端client 1和client 2,5个redis节点nodes (A, B, C, D and E)。
- client 1从A、B、C成功获取锁,从D、E获取锁网络超时
- 节点C的时钟不准确(如时钟跳跃),导致锁快速超时(算法第4点)
- client 2从C、D、E成功获取锁,从A、B获取锁网络超时
- 这样client 1和client 2都获得了锁
对于步骤2,还有一种情况,比如节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了;节点C重启后,client2从C、D、E成功获取锁
对于这两种情况,redis作者antirez给出了两种人为补偿措施
- 一时钟问题,不允许人员修改时间
- 二节点重启,提出延迟重启的概念,即一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,等待的时间大于锁的有效时间。采用这种方式,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响
Redlock的问题,最关键的一点在于Redlock需要客户端去保证写入的一致性,后端5个节点完全独立,所有的客户端都得操作这5个节点。如果5个节点有一个leader,客户端只要从leader获取锁,其他节点能同步leader的数据,这样,分区、超时、冲突等问题都不会存在。所以为了保证分布式锁的正确性,我觉得使用强一致性的分布式协调服务能更好的解决问题
而强一致问题,zk可以完成,zk是个CP系统,zk内部机制就保证了各数据的一致性
分布式锁
到此,对分布式锁的实现可以总结一下
zookeeper可靠性比redis强太多,只是效率低了点,如果并发量不是特别大,追求可靠性,首选zookeeper
为了效率,则首选redis实现
总结
除了分布式锁,还有一个常用场景:master选举。在curator中也有相应封装:LeaderSelector;具体实现可以自行阅读源码
