标题有些吸引眼球了,但并不浮夸,甚至还会远远超过百万,现在的平均响应时间在1ms内,0.08ms左右
如此高的QPS,如此低的AVG,为什么会有如此效果,关键点还是在多级缓存上
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流
概述
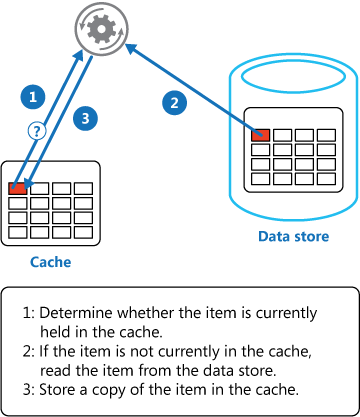
上图基本上就是查询的通用方案,缓存中是否存在,存在就返回,不存在再查询Db,查询到的结果load进缓存
实践
缓存,逃不过三种操作,创建、查询、删除
此实践可能不保证全场景通用,但满足当前系统各项指标,当然没有完美的方案,只有适合的方案。
下面的时序图中,cache lv1是指本地缓存,cache lv2是cache cluster
查询
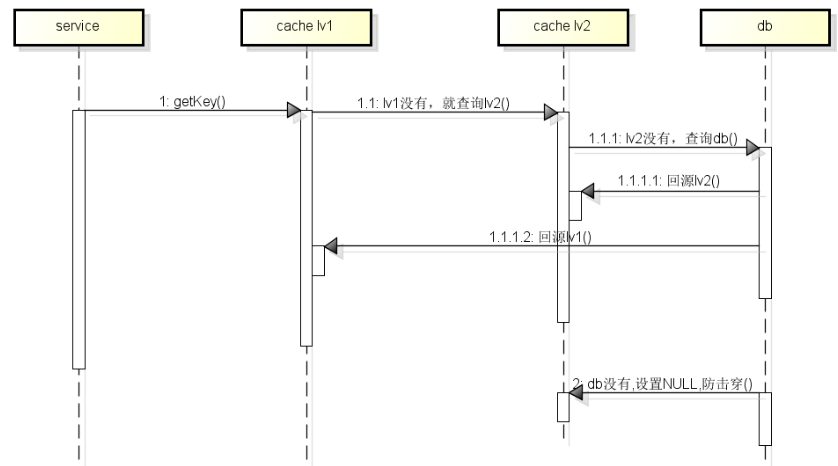
查询过程:
从一级缓存开始查,如果没有,再向下一级查询,直到db
注意点:
- 一直查到db时,需要回源各级cache
- 防止击穿,需要在cache中填充value
创建
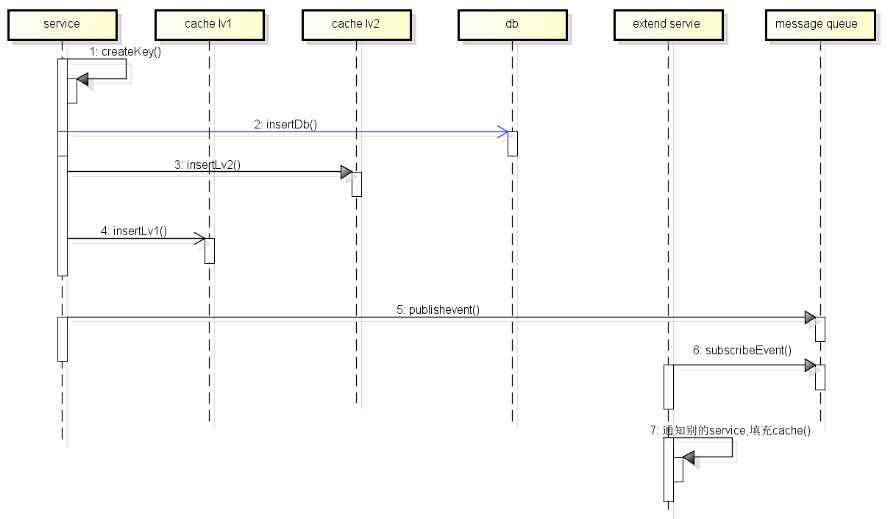
创建过程:
- 创建cacheObject
- 放入Db(为了性能,以及db的降级,这儿可以引入异步开关)
- 放入cache lv2
- 放入cache lv1
- publish创建成功消息
- 消息监听服务会通知其它服务更新本地缓存
注意点:
- 到底是先放入Db,还是先放入cache
- db与cache的一致性保障
删除
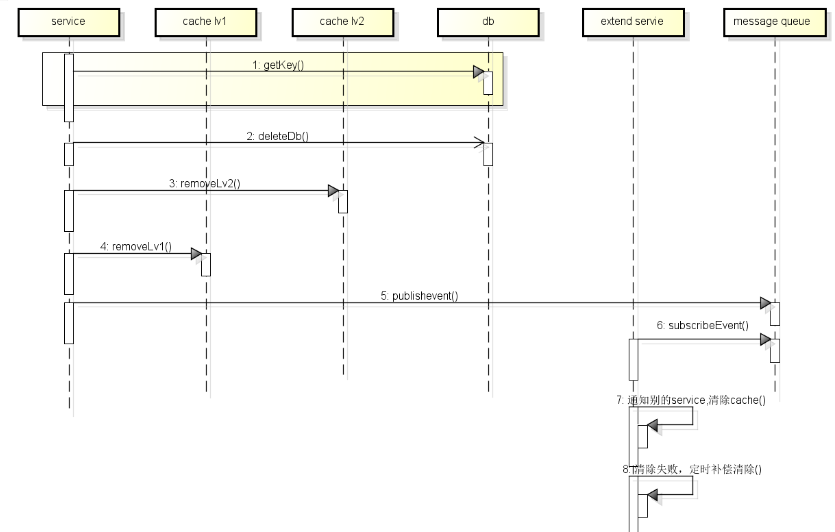
删除过程:
- 通过key查询cacheobject
- 清除db
- 清除各级cache
- publish消除成功消息
- 监听服务清除其它服务的本地缓存
注意点:
- 先清除db还是cache
- Db与cache的一致性保障
缓存操作模式
除了创建,查询,删除,还有更新操作;但我们业务场景没有。
对于我们的实践是不是放之四海而皆准,肯定是不行的。不以业务为基础的设计都是无根之木
先看下业界常见的操作缓存模式
更新缓存的的Design Pattern有四种:Cache aside, Read through, Write through, Write behind caching
Cache aside
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
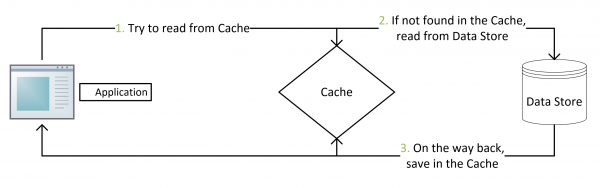

这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必须在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
Cache Aside,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
Read Through
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
这似乎很像guave的LoadCache
Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
Write Back
在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
在wikipedia上有一张write back的流程图,基本逻辑如下:
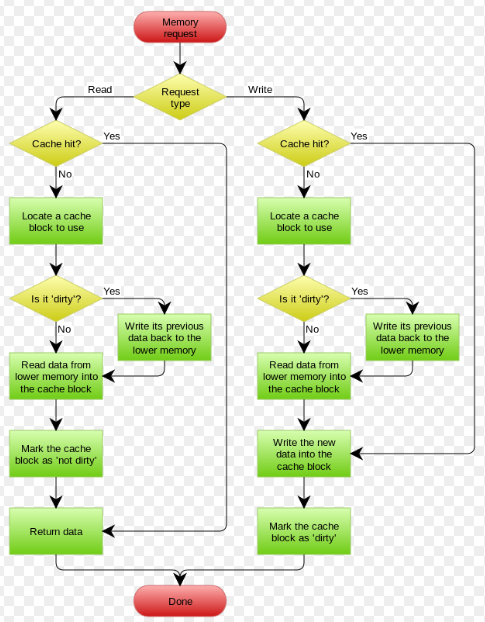
在游戏开发中基本上都是使用这种模式
但他也有缺点:
- 数据不是强一致性
- 数据可能会丢失
- 逻辑比较复杂
争论
- 一致性问题
这儿的一致性是说强一致性,在分布式环境下,保证强一致性促使系统复杂性增加,或者性能有所下降。所以现在一般对非强制性业务场景都使用最终一致性解决。一致性的解读可以看看《zookeeper-paxos》,在我们实践时,在删除操作时,在清理失败时也通过补偿操作去尝试清除。 - 到底是update cache,还是delete cache
其实任务技术手段都是看业务场景的,不能一概而论- update cache
这个在并发写时,A1写db,B1写db,B2写cache,A2写cache;这时就出现db与Cache不一致的问题
主动更新缓存,如果cacheobject复杂,需要Db与cache的多次交互,虽然减少了一次cache miss,但却增加了系统复杂度,得不偿失 - delete cache
这个不会有不一致问题了,但会造成cache miss,会不会造成热key穿透?
- update cache
- 是先操作Db,还是cache
假设先操作cache,再操作db;A B并发操作,A1 delete cache; B1 get cache –> miss –> select db –> load cache;A2 delete db;
此种情况就出现此key一直有效状态,如果没有设置超时时间,那会长期在缓存中。这是不是得先操作db呢?
一个操作先update db,再delte cache时失败了;那会数据库里是新数据,而缓存里是旧数据,业务无法接受。那是不是该先操作缓存呢?
是不是已经晕头了呢?
再有db主从架构中,主从不一致的情况,是不是没法玩了
所以还是开篇讲的没有放之四海而皆准的方案,只能寻找最适合的方案
在各种业务场景下,还是需要去寻找一些最佳实践,比如关注一下缓存过期策略、设置缓存过期时间
