算法虐我千万遍,我待算法如初恋;IT人永远逃脱不了的算法
概念
算法是特定问题求解步骤的描述,在计算机中表现为指令的有限序列
算法是独立存在的一种解决问题的方法和思想
对于算法而言,实现的语言并不重要,重要的是思想
特性
- 输入: 算法具有0个或多个输入
- 输出: 算法至少有1个或多个输出
- 有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
- 确定性:算法中的每一步都有确定的含义,不会出现二义性
- 可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
复杂度
一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量
时间复杂度
定义:如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n),它是n的某一函数T(n)称为这一算法的“时间复杂性”
1 | T(n) = O(f(n)) |
当输入量n逐渐加大时,时间复杂性的极限情形称为算法的“渐近时间复杂性”。
比如排序算法:可用算法执行中的数据比较次数与数据移动次数来衡量
空间复杂度
对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。
比如直接插入排序,需一个监视哨兵,空间复杂度是O(1) ,而一般的递归算法就要有O(n)的空间复杂度了,因为每次递归都要存储返回信息。
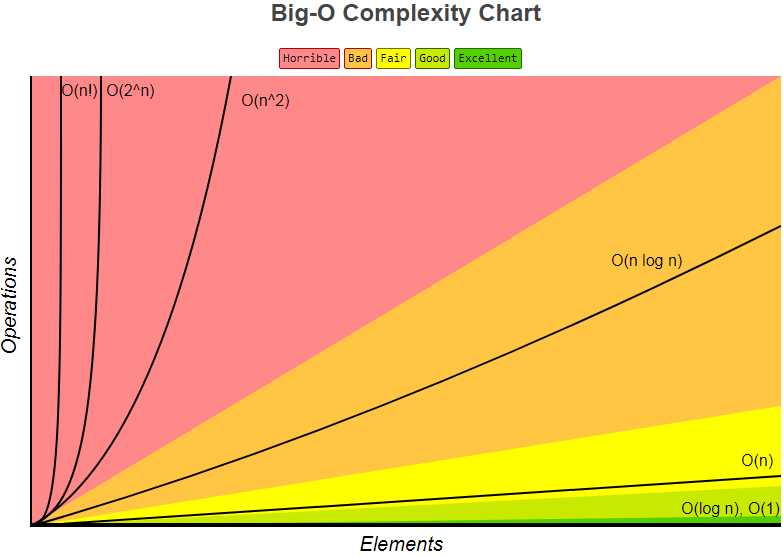
大O表示法
大O表示法被用来描述一个算法的性能或复杂度。大O表示法可以用来描述一个算法的最差情况,或者一个算法执行的耗时或占用空间(例如内存或磁盘占用)
假设一个算法的时间复杂度是 O(n),n在这里代表的意思就是数据的个数。
举个例子,如果你的代码用一个循环遍历 100 个元素,那么这个算法就是 O(n),n 为 100,所以这里的算法在执行时就要做 100 次工作
大O表示法就是将算法的所有步骤转换为代数项,然后排除不会对问题的整体复杂度产生较大影响的较低阶常数和系数,只关心复杂度最重要的部分1
2
3
4
5
6
7规律 Big-O
2 O(1) --> 就是一个常数
2n + 10 O(n) --> n 对整体结果会产生最大影响
5n^2 O(n^2) --> n^2 具有最大影响
O(log n),即对数复杂度(logarithmic complexity)。对数可以是ln(底数为e),log10,log2 或者以其它为底数,这无关紧要,它仍然是O(log n),正如O(2n^2) 和 O(100n^2) 都记为 O(n^2)。
示例
O(1)
O(1)表示该算法的执行时间(或执行时占用空间)总是为一个常量,不论输入的数据集是大是小1
2
3
4bool IsFirstElementNull(IList<string> elements)
{
return elements[0] == null;
}
O(N)
O(N)表示一个算法的性能会随着输入数据的大小变化而线性变化。下面的例子同时也表明了大O表示法其实是用来描述一个算法的最差情况的:在for循环中,一旦程序找到了输入数据中与第二个传入的string匹配时,程序就会提前退出,然而大O表示法却总是假定程序会运行到最差情况(在这个例子中,意味着大O会表示程序全部循环完成时的性能)1
2
3
4
5
6
7
8
9bool ContainsValue(IList<string> elements, string value)
{
foreach (var element in elements)
{
if (element == value) return true;
}
return false;
}
O(n²)
for循环嵌套的复杂度就是二次方的,因为你在一个线性操作里执行另外一个线性操作(或者说: n*n =n² )
如果嵌套层级不断深入的话,算法的性能将会变为O(N^3),O(N^4),以此类推1
2
3
4
5
6
7
8
9
10for (var outer = 0; outer < elements.Count; outer++)
{
for (var inner = 0; inner < elements.Count; inner++)
{
// Don't compare with self
if (outer == inner) continue;
if (elements[outer] == elements[inner]) return true;
}
}
O(2^N)
O(2^N)表示一个算法的性能将会随着输入数据的每次增加而增大两倍。O(2^N)的增长曲线是一条爆炸式增长曲线——开始时较为平滑,但数据增长后曲线增长非常陡峭。一个典型的O(2^N)方法就是裴波那契数列的递归计算实现1
2
3
4
5
6int Fibonacci(int number)
{
if (number <= 1) return number;
return Fibonacci(number - 2) + Fibonacci(number - 1);
}
(logn)
1 | i=1; |
比较
1 | O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n) |