/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ static final int MAXIMUM_CAPACITY = 1 << 30;
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
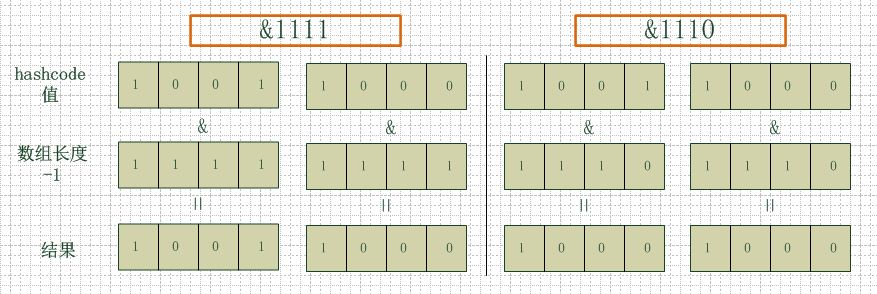
为了弄清楚这个问题,Bruce Eckel(Thinking in JAVA的作者)专程采访了java.util.hashMap的作者Joshua Bloch,此设计的原因 取模运算在包括Java在内的大多数语言中的效率都十分低下,而当除数为2的N次方时,取模运算将退化为最简单的位运算,其效率明显提升(按照Bruce Eckel给出的数据,大约可以提升5~8倍)
1 2 3 4 5 6 7
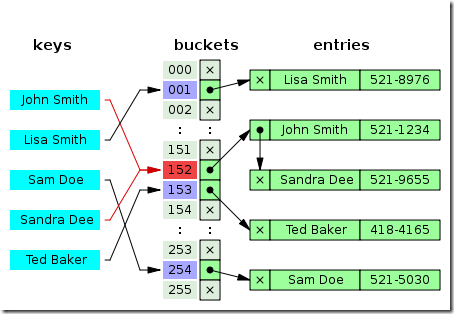
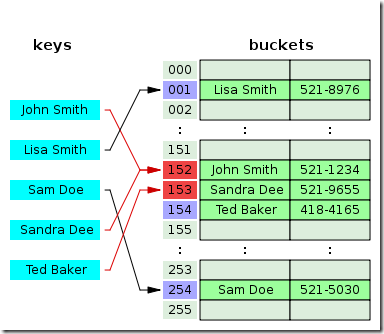
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
int capacity = 1; while (capacity < initialCapacity) capacity <<= 1;
threshold的值=容量*负载因子
看下roundUpToPowerOf2()
1 2 3 4 5 6
private static int roundUpToPowerOf2(int number) { // assert number >= 0 : "number must be non-negative"; return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; }
主要是Integer.highestOneBit
1 2 3 4 5 6 7 8 9
public static int highestOneBit(int i) { // HD, Figure 3-1 i |= (i >> 1); i |= (i >> 2); i |= (i >> 4); i |= (i >> 8); i |= (i >> 16); return i - (i >>> 1); }
/** * Offloaded version of put for null keys */ private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; }
这个逻辑比较简单
第一步,如果找到之前有key为null的key,进行一下value替换,返回oldValue
如果没有为null的key,那进行addEntry() 添加元素的主要方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; }
/** * A randomizing value associated with this instance that is applied to * hash code of keys to make hash collisions harder to find. If 0 then * alternative hashing is disabled. */ transient int hashSeed = 0; /** * Initialize the hashing mask value. We defer initialization until we * really need it. */ final boolean initHashSeedAsNeeded(int capacity) { boolean currentAltHashing = hashSeed != 0; boolean useAltHashing = sun.misc.VM.isBooted() && (capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD); boolean switching = currentAltHashing ^ useAltHashing; if (switching) { hashSeed = useAltHashing ? sun.misc.Hashing.randomHashSeed(this) : 0; } return switching; }
The seed parameter is a means for you to randomize the hash function. You should provide the same seed value for all calls to the hashing function in the same application of the hashing function. However, each invocation of your application (assuming it is creating a new hash table) can use a different seed, e.g., a random value.
Why is it provided?
One reason is that attackers may use the properties of a hash function to construct a denial of service attack. They could do this by providing strings to your hash function that all hash to the same value destroying the performance of your hash table. But if you use a different seed for each run of your program, the set of strings the attackers must use changes.
private abstract class HashIterator<E> implements Iterator<E> { Entry<K,V> next; // next entry to return int expectedModCount; // For fast-fail int index; // current slot Entry<K,V> current; // current entry final Entry<K,V> nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException();
这个内部遍历类使用了Fail-Fast机制
1 2 3 4 5 6 7 8
/** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ transient int modCount;