在DDD中Repository是一个相当重要的概念。聚合是战略与战术之间的交汇点。而管理聚合的正是Repository。
因为从战略层次,分而治之,我们会按领域、子域、界限上下文、聚合逐步划分降低系统复杂度;从战术层次,我们会从实体、值对象、聚合逐步归并,汇合。
也因此有人解析DDD关键就是两个字:分与合,分是手段,合是目的。
之前写的《DDD之Repository》,大致介绍了Repository作用。
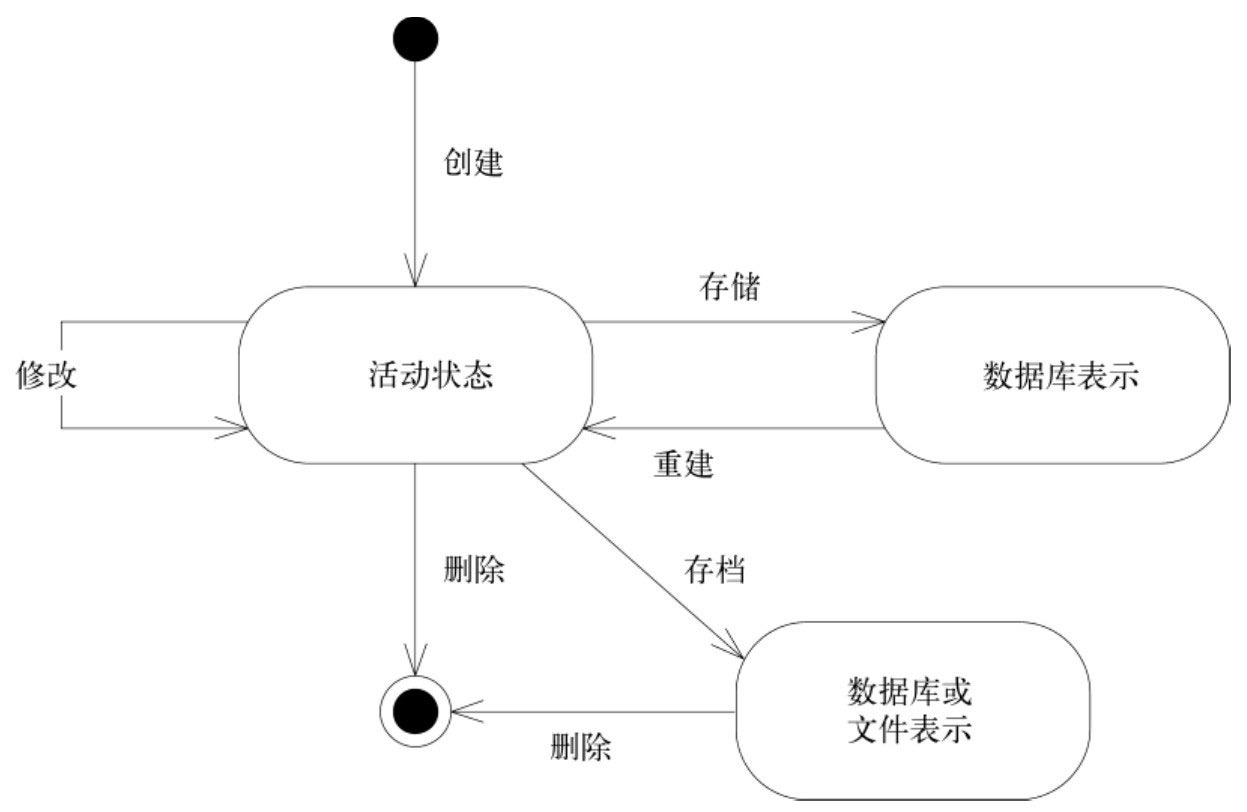
一是从“硬件”、“软件”、“固件”阐述了Repository的必要性,相对DAO,具有更高抽象,不再关心数据是从db,cache甚至第三方系统,Repository管理着数据在存档态与活跃态之间的转换
二是Respository与Domain Service之间的调用关系
虽然解释了不少,但也有些问题没有阐述清楚,借这篇再进一步详情补充说明下
常见的两个错误:
1、领域模型中不能出现技术词,所以在设计模型时,不要出现DAO之类的技术词。而在DDD中提出了Repository,一是从DDD统一语言角度,数据具体技术存储抽象为Repository;二是Repsotiory也表达模型概念。
2、Repository是DDD中作为DAO的替身,换汤不换药,所以从以前的XXXDao,变成了XXXRepository,然而Repository在DDD中并不是这么简单,它管理着聚合的生命周期,而其他实体对象由对应的聚合对象管理。
对于第一点,再详述下。在面向对象中有两种对象逻辑:单对象逻辑和集合对象逻辑。
如单纯的User对象,还有表示Collection
如果把Collection变成PersistentCollection,就是DB。
再进一步,看个小示例,一个办事处有很多的员工,以往模型表达为:1
2
3class Office {
List<User> users;
}
换一种方式:1
2
3class Office {
Users users;
}
使用Users来表达集合对象,这样原先使用List
而Repository就是代表了一种集合领域逻辑,如我们直接把UserRespository想像为Users处理。
使用这种方式一是能更好地表达模型,二也能解决在《处理业务逻辑的三种方式》 中提到的性能问题。
性能与模型的选择其实是在实践DDD过程中很多人的拦路虎。
如上面的Office对象,如果使用List来表达users集合数据,那当加载Office对象,users是不是必须加载出来,从模型完整性角度必须得加载出来,但加载出来必须带来性能损耗,如果users数量很大,不借助类似hibernate提供的懒加载机制来规避N+1带来的性能损耗,这个模型根本不可行。
这也是Repository不能按DDD原意来落地的原因。
进一步思考,其实上面的原因只是表象,背后是生命周期的管理。
生命周期管理
不论是设计,还是性能,对于聚合,除了显现的要求是聚合内的数据一致性。在数据库体系中,我们都是使用事务一致性来管理一致性和完整性。也是变相得把实体一致性与事务一致性两者的边界在同一边界上。
还有隐含的构建关系和级联生命周期。
比如:Order 与 OrderItem
创建:
1 | Order { |
那么当domain service去处理Order业务时
1 | OrderService { |
当orderRepository.save()时,不仅让order从活跃态变成持久态,还会把orderItem也由活跃态变成持久态。
当orderRepository.delete()时,也不仅删除了order,也得删除orderItem。才能保持一致性。
自然读取Order时,orderItems也得加载完整,保持模型的完整性。
这就是构建关系与级联生命周期。
怎么处理呢?
大致有三种方法
技术手段
在《DDD之Repository》提到的对象追踪,其实有很多的名字,也有叫Dirty Tracking
再配合延迟加载技术,达到了我们的目标:模型完整,落地可控。
失联领域 disconnected aggregate
1 | Order { |
在《IDDD》也提到,在聚合中使用 repository 来操作聚合。但不推荐,这只是延迟加载的一种形式。
把聚合看作一个整体,不用关心聚合内实体的改变,将所有改变,看作是聚合本身的改变。
在《IDDD》中也不推荐这样,给出的做法是在调用聚合方法前,先取出所需要的实体,也就是像在上述文章中所讲:Domain service不要依赖Repository。可以在application service里通过repository查出需要数据,再传给domain service,让domain service变得无状态。
但这种方式,看着是个方法,但实践时,有违直觉。什么意思呢?就是Aggregate依赖了Repository。相当于实体依赖了DAO,是不是很不应该?
其实domain service, entity, repository都属于domain层,那为什么同一层的类不能相互调用呢?
制定规则是来协调处理复杂性,都是基于认知或经验制定的,而不是为了规则而规则。
既然我们的认知是他们都在一层,应该可以调用,凭什么不能调用,不违背降低复杂性的前提下不要特意限制。
上文讲过Repository其实包含了一种集合逻辑,那我们把OrderRepository变名为Orders,也是一样的。
那么下面的代码是没有毛病的
1 | User { |
把List1
2
3Users implements List<User> {
}
到这儿,自然第一段代码,就变成了1
2
3User {
Users users;
}
这样写,是不是也没毛病? 把Users再替换成Repository
1 | User { |
是不是也没问题了,也就是User依赖了UserRepository。
由上面四段小代码,推导出了User依赖UserRepository的合理性与可行性,只是平常被DAO方式习惯了,以致于心理上有点别扭而已。这也变相说明了Repository不是DAO。
再进一步:
1 | Orders { |
这段代码,如果没有使用jpa,orm框架,也是有问题的。
为何?破坏了封装性。
因为在dao.insert里面必然会暴露order的内部数据
1 | OrderDao { |
我们使用对象建模,就是把业务逻辑 建模为数据变化,然后把数据的改变和改变数据的行为放一起
不同于面向过程是建模业务流程。
数据变化,以及生命周期变化是业务的核心逻辑。
对象状态变化来自队列和缓存,那么也要被domain封装对象生命周期。
因此代码得这样写,才不被破坏封装性:1
2
3
4
5Order {
void save(OrderRepo) {
orderRepo.save(thid.id,thid.time,...);
}
}
repo.save(order) 与 order.save(repo) 两种写法看似简单,背后的思想却让人的思考变得如此肤浅。
前一种写法,如果不与orm绑定,会造成封装性破坏,而且会从充血模型变成了贫血模型,table module。
后一种写法,在不与orm绑定前提下保护了封装性,但save行为赋给了当前对象,这是在面向对象早期流行的真实世界建模。
不管怎么写,从活跃态到归档态是很重要的行为,因为数据一致性是业务逻辑的核心。也说明了不管如何建模,都要考虑到技术实现,domain不是一片静土,没有约束的理想化实现,而是受特定技术栈与技术生态环境约束的实现。所以在分层时,有人认为基础设施层不是层的原因。
关联对象 association object
除了上面两种方式,还有在《分析模式》中提到的关联对象模式。
关联对象,顾名思义,就是将对象间的关联关系直接建模出来,然后再通过接口与抽象的隔离,把具体技术实现细节封装到接口的实现中。这样既可以保证概念上的统一,又能够避免技术实现上的限制。
总结
DDD中实体大致分成了两种:一是聚合根,二是聚合内实体。两者的生命周期管理也不一样,聚合根由repository管理,而其他实体由聚合根管理。
因此当在创建聚合根的时候,聚合根与其内部实体的生命周期有级联关系。通过三种方式可以实现这种级联关系。不管是何方式,要达到的目标:一是数据一致性,二是模型显现表达出来。
