常识系列,作为一名互联网门外汉的科普系列
堆外内存除了在像netty开源框架中,在平常项目中使用的比较少,在现前的项目中,QPS要求高的系统中,堆外内存作为其中一级缓存是相当有成效的。所以来学习一下,文中主要涉及到这三分部内容
- 堆外内存是什么?与堆内内存的区别
- 怎么分配,与GC的影响
- 开源框架使用
这篇文章写到最后,发现还只是回答了开源框架OHC的Why not use ByteBuffer.allocateDirect()?
概念
堆内内存
现在流行的还是使用分代管理方式
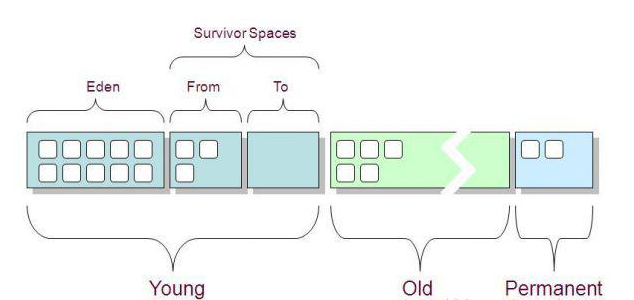
之前写过相关文章GC及JVM参数
在jvm参数中只要使用-Xms,-Xmx等参数就可以设置堆的大小和最大值
堆外内存
和堆内内存相对应,堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)
堆外内存有以下特点:
- 对于大内存有良好的伸缩性
- 对垃圾回收停顿的改善可以明显感觉到
- 在进程间可以共享,减少虚拟机间的复制
堆外内存分配与回收
其实堆外内存一直在使用,却没有真正关注过。最常见的nio,Netty,里面大量使用了堆外内存
这儿会涉及到很多知识点,一步步来,抽丝剥茧
Buffer
这儿回顾下io知识,java提供了两种io处理方式,一种是io,另一种是nio
Java NIO和IO之间最大的区别是IO是面向流(Stream)的,NIO是面向块(buffer)的,所以,这意味着什么?
面向流意味着从流中一次可以读取一个或多个字节,拿到读取的这些做什么你说了算,这里没有任何缓存(这里指的是使用流没有任何缓存,接收或者发送的数据是缓存到操作系统中的,流就像一根水管从操作系统的缓存中读取数据)而且只能顺序从流中读取数据,如果需要跳过一些字节或者再读取已经读过的字节,你必须将从流中读取的数据先缓存起来。
面向块的处理方式有些不同,数据是先被 读/写到buffer中的,根据需要你可以控制读取什么位置的数据。这在处理的过程中给用户多了一些灵活性,然而,你需要额外做的工作是检查你需要的数据是否已经全部到了buffer中,你还需要保证当有更多的数据进入buffer中时,buffer中未处理的数据不会被覆盖
对于stream流来讲,一个一个字节处理效率太差了,所以还提供了带buffer的bufferedStream
对就到api,就是1
2
3
4
5read()
read(byte b[])
write()
write(byte b[])
nio是面向buffer的,所以有专门抽象了Buffer
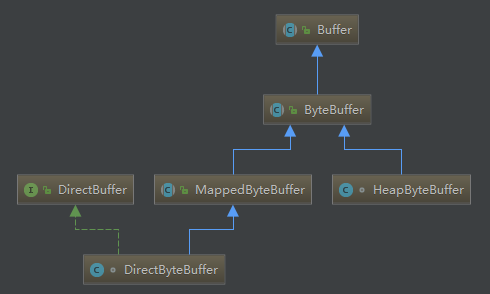
zero copy
虽然通过调节buffer的大小,使用bufferedstream可以提升性能,但还不够
还可以通过Zero-Copy大大提高了应用程序的性能,并且减少了kernel和user模式上下文的切换
这儿需要再深入底层机制,来看系统内核与应用程序的交互过程
linux科普
这儿再回顾一下linux相关知识点
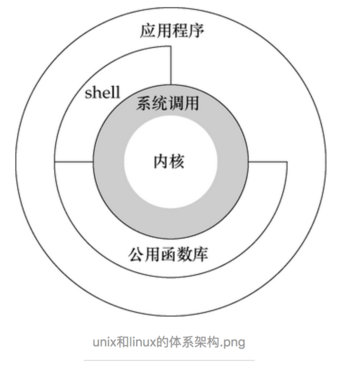
- 内核态:控制计算机的硬件资源,并提供上层应用程序运行的环境。比如socket I/0操作或者文件的读写操作等
- 用户态:上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源。
- 系统调用:为了使上层应用能够访问到这些资源,内核为上层应用提供访问的接口。
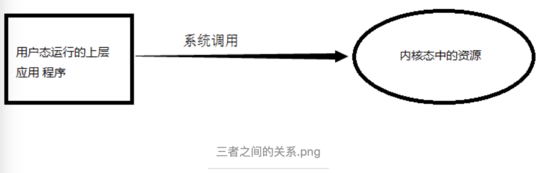
因此我们可以得知当我们通过JNI调用的native方法实际上就是从用户态切换到了内核态的一种方式。并且通过该系统调用使用操作系统所提供的功能。
Q:为什么需要用户进程(位于用户态中)要通过系统调用(Java中即使JNI)来调用内核态中的资源,或者说调用操作系统的服务了?
A:intel cpu提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为内核态。Ring3状态不能访问Ring0的地址空间,包括代码和数据。因此用户态是没有权限去操作内核态的资源的,它只能通过系统调用外完成用户态到内核态的切换,然后在完成相关操作后再有内核态切换回用户态。
鉴于linux系统的特性,IO之流程就如下图

copy过程
大部分web服务器都要处理大量的静态内容,而其中大部分都是从磁盘文件中读取数据然后写到socket中。这种操作对cpu的消耗是比较小的,但也是十分低效的:内核首先从磁盘文件读取数据,然后从内核空间将数据传到用户空间,应用程序又将数据从用户空间返回到内核空间然后传输给socket(如果好奇数据为何如此来回传输,请继续看下文)。实际上,应用程序就相当于是个低效的中间者,从磁盘拿数据放到socket。
read/write模式
代码抽象:1
2read(file, tmp_buf, len);
write(socket, tmp_buf, len);
首先调用read将静态内容,这里假设为文件A,读取到tmp_buf, 然后调用write将tmp_buf写入到socket中
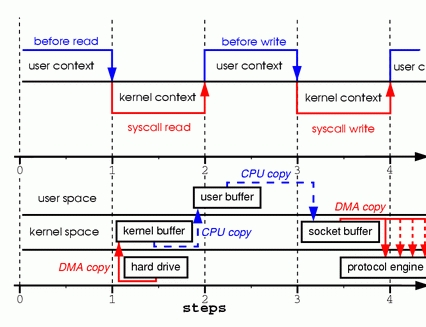
1、当调用 read 系统调用时,通过 DMA(Direct Memory Access)将数据 copy 到内核模式
2、然后由 CPU 控制将内核模式数据 copy 到用户模式下的 buffer 中
3、read 调用完成后,write 调用首先将用户模式下 buffer 中的数据 copy 到内核模式下的 socket buffer 中
4、最后通过 DMA copy 将内核模式下的 socket buffer 中的数据 copy 到网卡设备中传送。
从上面的过程可以看出,数据白白从内核模式到用户模式走了一圈,浪费了两次 copy(第一次,从kernel模式拷贝到user模式;第二次从user模式再拷贝回kernel模式,即上面4次过程的第2和3步骤。),而这两次 copy 都是 CPU copy,即占用CPU资源
sendfile模式
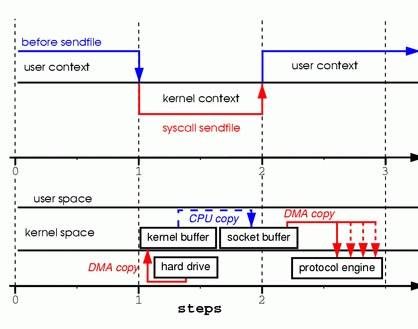
通过 sendfile 传送文件只需要一次系统调用,当调用 sendfile 时:
1、首先通过 DMA copy 将数据从磁盘读取到 kernel buffer 中
2、然后通过 CPU copy 将数据从 kernel buffer copy 到 sokcet buffer 中
3、最终通过 DMA copy 将 socket buffer 中数据 copy 到网卡 buffer 中发送
sendfile 与 read/write 方式相比,少了 一次模式切换一次 CPU copy。但是从上述过程中也可以发现从 kernel buffer 中将数据 copy 到socket buffer 是没必要的。
sendfile模式改进
Linux2.4 内核对 sendfile 做了改进,下图所示
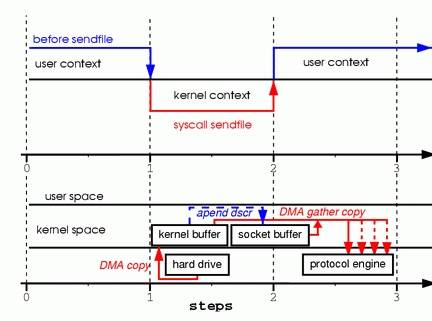
改进后的处理过程如下:
1、DMA copy 将磁盘数据 copy 到 kernel buffer 中
2、向 socket buffer 中追加当前要发送的数据在 kernel buffer 中的位置和偏移量
3、DMA gather copy 根据 socket buffer 中的位置和偏移量直接将 kernel buffer 中的数据 copy 到网卡上。
经过上述过程,数据只经过了 2 次 copy 就从磁盘传送出去了。(事实上这个 Zero copy 是针对内核来讲的,数据在内核模式下是 Zero-copy 的)。
当前许多高性能 http server 都引入了 sendfile 机制,如 nginx,lighttpd 等。
java zero copy
Zero-Copy技术省去了将操作系统的read buffer拷贝到程序的buffer,以及从程序buffer拷贝到socket buffer的步骤,直接将read buffer拷贝到socket buffer. Java NIO中的FileChannal.transferTo()方法就是这样的实现
1 | public void transferTo(long position,long count,WritableByteChannel target); |
transferTo()方法将数据从一个channel传输到另一个可写的channel上,其内部实现依赖于操作系统对zero copy技术的支持。在unix操作系统和各种linux的发型版本中,这种功能最终是通过sendfile()系统调用实现。下边就是这个方法的定义:1
2#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
可以通过调用transferTo()方法来替代上边的File.read()、Socket.send()
通过transferTo实现数据传输的路径:
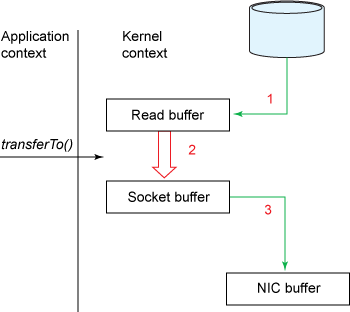
展示了内核态、用户态的切换情况:
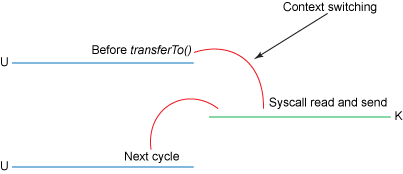
使用transferTo()方式所经历的步骤:
1、transferTo调用会引起DMA将文件内容复制到读缓冲区(内核空间的缓冲区),然后数据从这个缓冲区复制到另一个与socket输出相关的内核缓冲区中。
2、第三次数据复制就是DMA把socket关联的缓冲区中的数据复制到协议引擎上发送到网络上。
这次改善,我们是通过将内核、用户态切换的次数从四次减少到两次,将数据的复制次数从四次减少到三次(只有一次用到cpu资源)。但这并没有达到我们零复制的目标。如果底层网络适配器支持收集操作的话,我们可以进一步减少内核对数据的复制次数。
在内核为2.4或者以上版本的linux系统上,socket缓冲区描述符将被用来满足这个需求。这个方式不仅减少了内核用户态间的切换,而且也省去了那次需要cpu参与的复制过程。
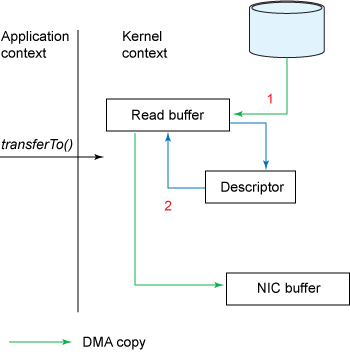
从用户角度来看依旧是调用transferTo()方法,但是其本质发生了变化:
1、调用transferTo方法后数据被DMA从文件复制到了内核的一个缓冲区中。
2、数据不再被复制到socket关联的缓冲区中了,仅仅是将一个描述符(包含了数据的位置和长度等信息)追加到socket关联的缓冲区中。DMA直接将内核中的缓冲区中的数据传输给协议引擎,消除了仅剩的一次需要cpu周期的数据复制。
ByteBuffer创建
以上的知识点都是点缀,真正的主角上场了,看下java中是如何抽象上述理论的
ByteBuffer有两种分配buffer的方式:
分配HeapByteBuffer1
ByteBuffer buffer = ByteBuffer.allocate(int capacity);
分配DirectByteBuffer1
ByteBuffer buffer = ByteBuffer.allocateDirect(int capacity);
两者的区别,JDK里面说得很清楚
A byte buffer is either direct or non-direct. Given a direct byte buffer, the Java virtual machine will make a best effort to perform native I/O operations directly upon it. That is, it will attempt to avoid copying the buffer’s content to (or from) an intermediate buffer before (or after) each invocation of one of the underlying operating system’s native I/O operations.
A direct byte buffer may be created by invoking the allocateDirect factory method of this class. The buffers returned by this method typically have somewhat higher allocation and deallocation costs than non-direct buffers. The contents of direct buffers may reside outside of the normal garbage-collected heap, and so their impact upon the memory footprint of an application might not be obvious. It is therefore recommended that direct buffers be allocated primarily for large, long-lived buffers that are subject to the underlying system’s native I/O operations. In general it is best to allocate direct buffers only when they yield a measureable gain in program performance.
A direct byte buffer may also be created by mapping a region of a file directly into memory. An implementation of the Java platform may optionally support the creation of direct byte buffers from native code via JNI. If an instance of one of these kinds of buffers refers to an inaccessible region of memory then an attempt to access that region will not change the buffer’s content and will cause an unspecified exception to be thrown either at the time of the access or at some later time.
从文中大致可以看到DirectByteBuffer的特点如下:
- 对于native IO operation,JVM会有最佳的性能效果(它不需要一个中间缓冲区,而是可以直接使用,避免了将buffer中的数据再复制到中间缓冲区)。
- 由于DirectByteBuffer分配与native memory中,不在heap区,不会受到heap区的gc影响。(一般在old gen的full gc才会收集。)
- 分配和释放需要更多的成本。

从上可以总结DirectByteBuffer大致的应用场景如下(socket通信和大文件处理还是比较适用的):
- 频繁的native IO操作。
- 系统的要求处理响应速度快和稳定,即高吞吐和低延迟。
- ByteBuffer的生命周期长且容量需求较大,会占用较多的内存空间。
看下代码,更直观一些
HeapByteBuffer
分配在堆上的,直接由Java虚拟机负责垃圾收集,你可以把它想象成一个字节数组的包装类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class HeapByteBuffer
extends ByteBuffer
{
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
}
}
public abstract class ByteBuffer
extends Buffer
implements Comparable<ByteBuffer>
{
// These fields are declared here rather than in Heap-X-Buffer in order to
// reduce the number of virtual method invocations needed to access these
// values, which is especially costly when coding small buffers.
//
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly; // Valid only for heap buffers
// Creates a new buffer with the given mark, position, limit, capacity,
// backing array, and array offset
//
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
DirectByteBuffer
这个类就没有HeapByteBuffer简单了
DirectByteBuffer结构
1 | DirectByteBuffer(int cap) { // package-private |
Bits.reserveMemory(size, cap) 方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32static void reserveMemory(long size, int cap) {
synchronized (Bits.class) {
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
// -XX:MaxDirectMemorySize limits the total capacity rather than the
// actual memory usage, which will differ when buffers are page
// aligned.
if (cap <= maxMemory - totalCapacity) {
reservedMemory += size;
totalCapacity += cap;
count++;
return;
}
}
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException x) {
// Restore interrupt status
Thread.currentThread().interrupt();
}
synchronized (Bits.class) {
if (totalCapacity + cap > maxMemory)
throw new OutOfMemoryError("Direct buffer memory");
reservedMemory += size;
totalCapacity += cap;
count++;
}
}
在DirectByteBuffer中,首先向Bits类申请额度,Bits类有一个全局的totalCapacity变量,记录着全部DirectByteBuffer的总大小,每次申请,都先看看是否超限,堆外内存的限额默认与堆内内存(由-Xmx 设定)相仿,可用 -XX:MaxDirectMemorySize 重新设定。
如果不指定,该参数的默认值为Xmx的值减去1个Survior区的值。
如设置启动参数-Xmx20M -Xmn10M -XX:SurvivorRatio=8,那么申请20M-1M=19M的DirectMemory
如果已经超限,会主动执行Sytem.gc(),期待能主动回收一点堆外内存。
System.gc()会触发一个full gc,当然前提是你没有显示的设置-XX:+DisableExplicitGC来禁用显式GC。并且你需要知道,调用System.gc()并不能够保证full gc马上就能被执行。
所以在使用netty这类框架时,一定要注意JVM优化,如果DisableExplicitGC那就可能会OOM了
然后休眠一百毫秒,看看totalCapacity降下来没有,如果内存还是不足,就抛出OOM异常。如果额度被批准,就调用大名鼎鼎的sun.misc.Unsafe去分配内存,返回内存基地址1
2
3// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;
这样我们后面通过JNI对这个堆外内存操作时都是通过这个address来实现的了。
Unsafe的C++实现在此,标准的malloc。然后再调一次Unsafe把这段内存给清零。跑个题,Unsafe的名字是提醒大家这个类只给Sun自家用的
JDK7开始,DirectByteBuffer分配内存时默认已不做分页对齐,不会再每次分配并清零实际需要+分页大小(4k)的内存,这对性能应有较大提升,所以Oracle专门写在了Enhancements in Java I/O里。
最后,创建一个Cleaner,并把代表清理动作的Deallocator类绑定 – 降低Bits里的totalCapacity,并调用Unsafe调free去释放内存。Cleaner的触发机制后面再说。
DirectByteBuffer中1
2
3
4
5
6
7
8byte _get(int i) { // package-private
return unsafe.getByte(address + i);
}
void _put(int i, byte b) { // package-private
unsafe.putByte(address + i, b);
}
在前面我们说过,在linux中内核态的权限是最高的,那么在内核态的场景下,操作系统是可以访问任何一个内存区域的,所以操作系统是可以访问到Java堆的这个内存区域的。
Q:那为什么操作系统不直接访问Java堆内的内存区域了?
A:这是因为JNI方法访问的内存区域是一个已经确定了的内存区域地质,那么该内存地址指向的是Java堆内内存的话,那么如果在操作系统正在访问这个内存地址的时候,Java在这个时候进行了GC操作,而GC操作会涉及到数据的移动操作[GC经常会进行先标志在压缩的操作。即,将可回收的空间做标志,然后清空标志位置的内存,然后会进行一个压缩,压缩就会涉及到对象的移动,移动的目的是为了腾出一块更加完整、连续的内存空间,以容纳更大的新对象],数据的移动会使JNI调用的数据错乱。所以JNI调用的内存是不能进行GC操作的,JNI不能直接访问Java堆内的内存区域
Q:如上面所说,JNI不能直接访问Java堆内的内存区域,那该如何解决了?
A:①堆内内存与堆外内存之间数据拷贝的方式(并且在将堆内内存拷贝到堆外内存的过程JVM会保证不会进行GC操作):
比如我们要完成一个从文件中读数据到堆内内存的操作,即FileChannelImpl.read(HeapByteBuffer)。这里实际上File I/O会将数据读到堆外内存中,然后堆外内存再讲数据拷贝到堆内内存,这样我们就读到了文件中的内存。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public int read(ByteBuffer var1) throws IOException {
this.ensureOpen();
if(!this.readable) {
throw new NonReadableChannelException();
} else {
Object var2 = this.positionLock;
synchronized(this.positionLock) {
int var3 = 0;
int var4 = -1;
try {
this.begin();
var4 = this.threads.add();
if(!this.isOpen()) {
byte var12 = 0;
return var12;
} else {
do {
//关键点在这行
var3 = IOUtil.read(this.fd, var1, -1L, this.nd);
} while(var3 == -3 && this.isOpen());
int var5 = IOStatus.normalize(var3);
return var5;
}
} finally {
this.threads.remove(var4);
this.end(var3 > 0);
assert IOStatus.check(var3);
}
}
}
}
IOUtil1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
if (var1.isReadOnly()) {
throw new IllegalArgumentException("Read-only buffer");
} else if (var1 instanceof DirectBuffer) {
return readIntoNativeBuffer(var0, var1, var2, var4);
} else {
// 分配临时的堆外内存
ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());
int var7;
try {
// File I/O 操作会将数据读入到堆外内存中
int var6 = readIntoNativeBuffer(var0, var5, var2, var4);
var5.flip();
if (var6 > 0) {
// 将堆外内存的数据拷贝到堆内内存中
var1.put(var5);
}
var7 = var6;
} finally {
// 里面会调用DirectBuffer.cleaner().clean()来释放临时的堆外内存
Util.offerFirstTemporaryDirectBuffer(var5);
}
return var7;
}
}
而写操作则反之,我们会将堆内内存的数据线写到对堆外内存中,然后操作系统会将堆外内存的数据写入到文件中。
假设我们要从网络中读入一段数据,再把这段数据发送出去的话,采用Non-direct ByteBuffer的流程是这样的:
网络 –> 临时的Direct ByteBuffer –> 应用 Non-direct ByteBuffer –> 临时的Direct ByteBuffer –> 网络
② 直接使用堆外内存,如DirectByteBuffer:
这种方式是直接在堆外分配一个内存(即,native memory)来存储数据,
程序通过JNI直接将数据读/写到堆外内存中。因为数据直接写入到了堆外内存中,所以这种方式就不会再在JVM管控的堆内再分配内存来存储数据了,也就不存在堆内内存和堆外内存数据拷贝的操作了。这样在进行I/O操作时,只需要将这个堆外内存地址传给JNI的I/O的函数就好了。
采用Direct ByteBuffer的流程是这样的:
网络 –> 应用 Direct ByteBuffer –> 网络
可以看到,除开构造和析构临时Direct ByteBuffer的时间外,起码还能节约两次内存拷贝的时间。那么是否在任何情况下都采用Direct Buffer呢?
不是。对于大部分应用而言,两次内存拷贝的时间几乎可以忽略不计,而构造和析构DirectBuffer的时间却相对较长。在JVM的实现当中,某些方法会缓存一部分临时Direct ByteBuffer,意味着如果采用Direct ByteBuffer仅仅能节约掉两次内存拷贝的时间,
而无法节约构造和析构的时间。就用Sun的实现来说,write(ByteBuffer)和read(ByteBuffer)方法都会缓存临时Direct ByteBuffer,而write(ByteBuffer[])和read(ByteBuffer[])每次都生成新的临时Direct ByteBuffer。
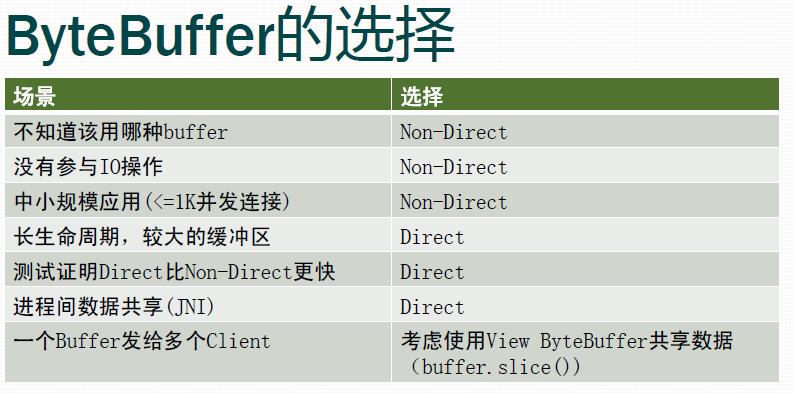
根据这些区别,如下的建议:
- 如果你做中小规模的应用(在这里,应用大小是按照使用ByteBuffer的次数和规模来做划分的),而且并不在乎这该死的细节问题,请选择Non-direct ByteBuffer
- 如果采用Direct ByteBuffer后性能并没有出现你所期待的变化,请选择Non-direct ByteBuffer
- 如果没有Direct ByteBuffer Pool,尽量不要使用Direct ByteBuffer
- 除非你确定该ByteBuffer会长时间存在,并且和外界有频繁交互,可采用Direct ByteBuffer
- 如果采用Non-direct ByteBuffer,那么采用非聚集(gather)的write/read(ByteBuffer)效果反而可能超出聚集的write/read(ByteBuffer[]),因为聚集的write/read的临时Direct ByteBuffer是非缓存的
基本上,采用Non-direct ByteBuffer总是对的!因为内存拷贝需要的开销对大部分应用而言都可以忽略不计。
ByteBuffer回收
HeapByteBuffer就不要说了,GC就帮忙处理了。这儿主要说下DirectByteBuffer
基于GC回收DirectByteBuffer
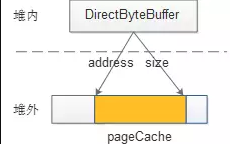
存在于堆内的DirectByteBuffer对象很小,只存着基地址和大小等几个属性,和一个Cleaner,但它代表着后面所分配的一大段内存,是所谓的冰山对象。
在内存中基本是这样子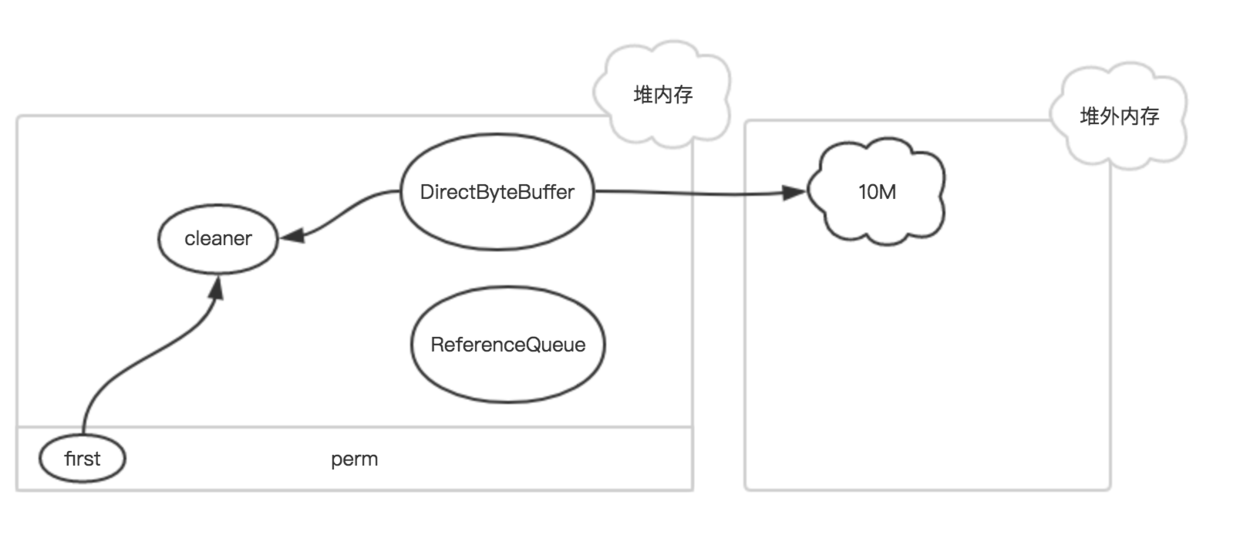
其中first是Cleaner类的静态变量,Cleaner对象在初始化时会被添加到Clener链表中,和first形成引用关系,ReferenceQueue是用来保存需要回收的Cleaner对象。
如果该DirectByteBuffer对象在一次GC中被回收了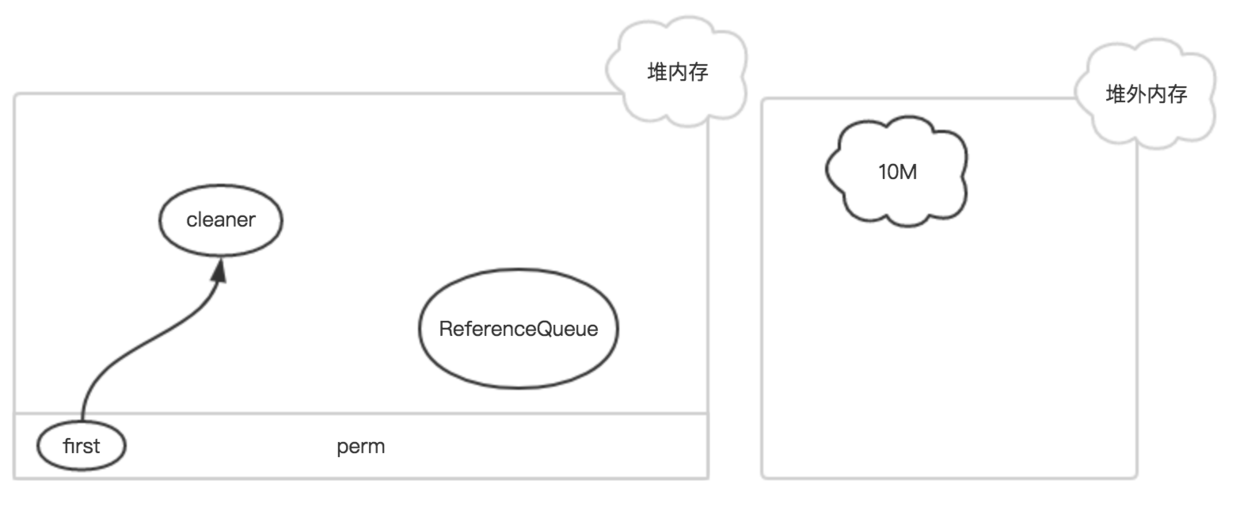
此时,只有Cleaner对象唯一保存了堆外内存的数据(开始地址、大小和容量),在下一次Full GC时,把该Cleaner对象放入到ReferenceQueue中,并触发clean方法。
快速回顾一下堆内的GC机制,当新生代满了,就会发生young gc;如果此时对象还没失效,就不会被回收;撑过几次young gc后,对象被迁移到老生代;当老生代也满了,就会发生full gc。
这里可以看到一种尴尬的情况,因为DirectByteBuffer本身的个头很小,只要熬过了young gc,即使已经失效了也能在老生代里舒服的呆着,不容易把老生代撑爆触发full gc,如果没有别的大块头进入老生代触发full gc,就一直在那耗着,占着一大片堆外内存不释放。
这时,就只能靠前面提到的申请额度超限时触发的system.gc()来救场了。但这道最后的保险其实也不很好,首先它会中断整个进程,然后它让当前线程睡了整整一百毫秒,而且如果gc没在一百毫秒内完成,它仍然会无情的抛出OOM异常。还有,万一,万一大家迷信某个调优指南设置了-DisableExplicitGC禁止了system.gc(),那就不好玩了。
所以,堆外内存还是自己主动点回收更好,比如Netty就是这么做的
主动回收DirectByteBuffer
对于Sun的JDK这其实很简单,只要从DirectByteBuffer里取出那个sun.misc.Cleaner,然后调用它的clean()就行。
1 | ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024 * 1024 * 500); |
前面说的,clean()执行时实际调用的是被绑定的Deallocator类,这个类可被重复执行,释放过了就不再释放。所以GC时再被动执行一次clean()也没所谓。
在Netty里,因为不确定跑在Sun的JDK里(比如安卓),所以多废了些功夫来确定Cleaner的存在
Cleaner类
1 | public class Cleaner extends PhantomReference<Object> { |
PhantomReference 这个虚引用类很少见,它是java中最弱的引用类型
PhantomReference 类只能用于跟踪对被引用对象即将进行的收集。
同样,它还能用于执行 pre-mortem 清除操作。 PhantomReference 必须与 ReferenceQueue 类一起使用。需要 ReferenceQueue 是因为它能够充当通知机制。当垃圾收集器确定了某个对象是虚可及对象时, PhantomReference 对象就被放在它的 ReferenceQueue 上。将 PhantomReference 对象放在 ReferenceQueue 上也就是一个通知,表明 PhantomReference 对象引用的对象已经结束,可供收集了。这使您能够刚好在对象占用的内存被回收之前采取行动。
当GC时发现它除了PhantomReference外已不可达(持有它的DirectByteBuffer失效了),就会把它放进 Reference类pending list静态变量里。然后另有一条ReferenceHandler线程,名字叫 “Reference Handler”的,关注着这个pending list,如果看到有对象类型是Cleaner,就会执行它的clean(),其他类型就放入应用构造Reference时传入的ReferenceQueue中,这样应用的代码可以从Queue里拖出这些理论上已死的对象,做爱做的事情——这是一种比finalizer更轻量更好的机制。
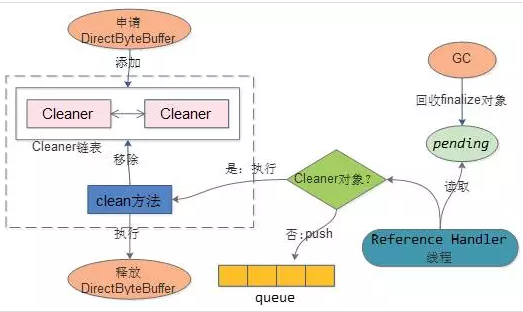
比如创建DirectByteBuffer,会新建Cleaner对象,该对象添加到Cleaner链表中。
对象被GC,如果是Cleaner对象,则会执行该对象的clean方法,
Clean方法会将对应的cleaner对象从链表中移除,同时会回收DirectByteBuffer申请的资源
看下ReferenceHandler源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50/* High-priority thread to enqueue pending References
*/
private static class ReferenceHandler extends Thread {
ReferenceHandler(ThreadGroup g, String name) {
super(g, name);
}
public void run() {
for (;;) {
Reference<Object> r;
synchronized (lock) {
if (pending != null) {
r = pending;
pending = r.discovered;
r.discovered = null;
} else {
// The waiting on the lock may cause an OOME because it may try to allocate
// exception objects, so also catch OOME here to avoid silent exit of the
// reference handler thread.
//
// Explicitly define the order of the two exceptions we catch here
// when waiting for the lock.
//
// We do not want to try to potentially load the InterruptedException class
// (which would be done if this was its first use, and InterruptedException
// were checked first) in this situation.
//
// This may lead to the VM not ever trying to load the InterruptedException
// class again.
try {
try {
lock.wait();
} catch (OutOfMemoryError x) { }
} catch (InterruptedException x) { }
continue;
}
}
// Fast path for cleaners
if (r instanceof Cleaner) {
((Cleaner)r).clean();
continue;
}
ReferenceQueue<Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
}
}
}
回顾下Finalize回收
sun不推荐实现finalize,实际上JDK内部很多类都实现了finalize。
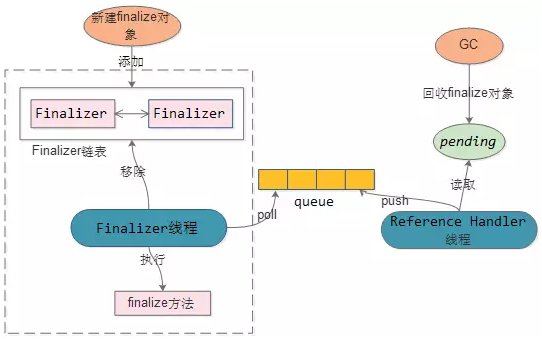
如果对象实现了finalize,在对象初始化后,会封装成Finalizer对象添加到 Finalizer链表中。
对象被GC时,如果是Finalizer对象,会将对象赋值到pending对象。Reference Handler线程会将pending对象push到queue中。
Finalizer线程poll到对象,先删除掉Finalizer链表中对应的对象,然后再执行对象的finalize方法(一般为资源的销毁)
方案的缺点:
- 对象至少跨越2个GC,垃圾对象无法及时被GC掉,并且存在多次拷贝。影响YGC和FGC
- Finalizer线程优先级较低,会导致finalize方法延迟执行
开源堆外缓存框架
- Ehcache 3.0:3.0基于其商业公司一个非开源的堆外组件的实现。
- Chronical Map:OpenHFT包括很多类库,使用这些类库很少产生垃圾,并且应用程序使用这些类库后也很少发生Minor GC。类库主要包括:Chronicle Map,Chronicle Queue等等。
- OHC:来源于Cassandra 3.0, Apache v2。
- Ignite: 一个规模宏大的内存计算框架,属于Apache项目。
OHC
DirectByteBuffer是使用unsafe(JNI)申请堆外空间(unsafe.allocateMemory(size))。还有一种申请堆外空间的手段:JNA。
JNA的描述(https://github.com/java-native-access/jna)
JNA provides Java programs easy access to native shared libraries without writing anything but Java code - no JNI or native code is required
堆外缓存OHC便是使用JNA来申请堆外空间。
线下测试:JNA内存申请的性能是unsafe(JNI)的2倍。
Why not use ByteBuffer.allocateDirect()?
TL;DR allocating off-heap memory directly and bypassing ByteBuffer.allocateDirect is very gentle to the GC and we have explicit control over memory allocation and, more importantly, free. The stock implementation in Java frees off-heap memory during a garbage collection - also: if no more off-heap memory is available, it likely triggers a Full-GC, which is problematic if multiple threads run into that situation concurrently since it means lots of Full-GCs sequentially. Further, the stock implementation uses a global, synchronized linked list to track off-heap memory allocations.
This is why OHC allocates off-heap memory directly and recommends to preload jemalloc on Linux systems to improve memory managment performance.
这是OHC的wiki说明
其实OHC实现了JNI(malloc),JNA(jemalloc)两种方式,默认使用了JNA(jemalloc),性能的提升最关键的是malloc与jemalloc的区别了
在org.caffinitas.ohc.chunked.Uns类中,创建IAllocator类片段代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18private static final String __ALLOCATOR = System.getProperty(OHCacheBuilder.SYSTEM_PROPERTY_PREFIX + "allocator");
IAllocator alloc;
String allocType = __ALLOCATOR != null ? __ALLOCATOR : "jna";
switch (allocType)
{
case "unsafe":
alloc = new UnsafeAllocator();
LOGGER.info("OHC using sun.misc.Unsafe memory allocation");
break;
case "jna":
default:
alloc = new JNANativeAllocator();
LOGGER.info("OHC using JNA OS native malloc/free");
}
allocator = alloc;
}
UnsafeAllocator1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Field field = sun.misc.Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (sun.misc.Unsafe) field.get(null);
public long allocate(long size)
{
try
{
return unsafe.allocateMemory(size);
}
catch (OutOfMemoryError oom)
{
return 0L;
}
}
JNANativeAllocator1
2
3
4
5
6
7
8
9
10
11public long allocate(long size)
{
try
{
return Native.malloc(size);
}
catch (OutOfMemoryError oom)
{
return 0L;
}
}
其它
OHC这只是一个开端,只是分配内存部分,它还有淘汰策略等等,之后说缓存时,再谈了
