一个简简单单的基础数据结构,却发展成了形形色色的消息队列中间件。世界就是如此奇妙。

如上图,一个简单的队列数据结构,由生产者往里插入内容,由消费者从里面获取内容进行消费,就构建出一个简单的消息队列模型。
消息模型有两种:
1、点对点模型:也叫消息队列模型。多个消费者共同消费同一个队列,效率高
2、发布/订阅模型:发送方也称之为发布者(Publisher),接受方称为订阅者(Subscriber)。与点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。

一个简单的Kafka架构图:
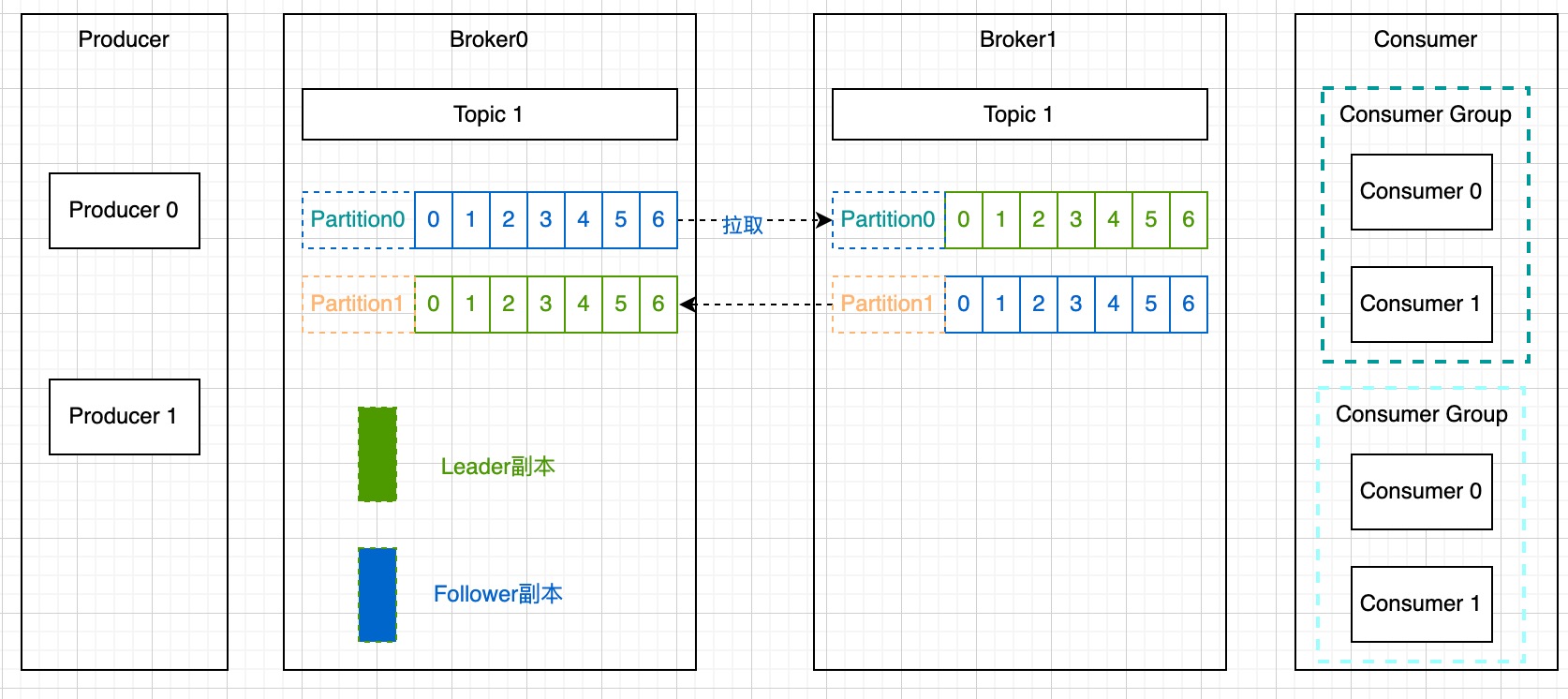
生产者:Producer
向主题发布新消息的应用程序。
Broker
负责接收和处理客户端发送过来的请求,以及对消息进行持久化。一个Kafka集群由多个Broker组成。
消费者:Consumer
从主题订阅新消息的应用程序。
消息队列一般有两种实现方式
(1)Push(推模式)
(2)Pull(拉模式)
那么 Kafka Consumer 究竟采用哪种方式进行消费的呢?其实 Kafka Consumer 采用的是主动拉取 Broker数据进行消费的即 Pull 模式。这两种方式各有优劣,我们来分析一下:
1)、为什么不采用Push模式?如果是选择 Push 模式最大缺点就是 Broker 不清楚 Consumer 的消费速度,且推送速率是 Broker 进行控制的, 这样很容易造成消息堆积,如果 Consumer 中执行的任务操作是比较耗时的,那么 Consumer 就会处理的很慢, 严重情况可能会导致系统 Crash。
2)、为什么采用Pull模式?如果选择 Pull 模式,这时 Consumer 可以根据自己的情况和状态来拉取数据, 也可以进行延迟处理。但是 Pull 模式也有不足,Kafka 又是如何解决这一问题?如果 Kafka Broker 没有消息,这时每次 Consumer 拉取的都是空数据, 可能会一直循环返回空数据。 针对这个问题,Consumer 在每次调用 Poll() 消费数据的时候,顺带一个 timeout 参数,当返回空数据的时候,会在 Long Polling 中进行阻塞,等待 timeout 再去消费,直到数据到达。
主题:Topic
主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition
一个有序不变的消息序列。每个主题下可以有多个分区。
分区的主要原因,为了实现系统的高伸缩性(Scalability)。不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。
分区策略:决定生产者将消息发送到哪个分区的算法。
1、轮询策略,Round-robin策略,即顺序分配。
2、随机策略,Randomness策略。所谓随机就是随意地将消息放置在做任意一个分区上。
3、Key-ordering策略。
消费者组:Consumer Group
指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。
为什么要引入消费者组?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
Kafka 仅仅使用 Consumer Group 这一种机制,却同时实现了传统消息引擎系统的两大模型:如果所有实例都属于同一个 Group,那么它实现的就是消息队列模型;如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
Kafka Consumer Group 特点如下:
1、 每个 Consumer Group 有一个或者多个 Consumer
2、每个 Consumer Group 拥有一个公共且唯一的 Group ID
1 | spring.kafka.consumer.group-id |
3、Consumer Group 在消费 Topic 的时候,Topic 的每个 Partition 只能分配给组内的某个 Consumer,只要被任何 Consumer 消费一次, 那么这条数据就可以认为被当前 Consumer Group 消费成功
最理想的情况是Consumer实例的数量应该等于该Group订阅主题的分区总数。例如:Consumer Group 订阅了 3个主题,分别是A、B、C,它们的分区数依次是1、2、3,那么通常情况下,为该Group 设置6个Consumer实例是比较理想的情形。
如果设置小于或大于6的实例可以吗?当然可以,如果你有3个实例,那么平均下来每个实例大约消费2个分区(6/3=2);如果你设置了9个实例,那么很遗憾,有3个实例(9-6=3)将不会被分配任何分区,它们永远处于空闲状态
副本机制(Replication)
也称之为备份机制,通常是指分布式系统在多台网络互联的机器上保存有相同的数据拷贝。副本机制的好处:
1、提供数据冗余。即使系统部分组件失效,系统依然能够继续运转,因而增加了整体可用性以及数据持久性。
2、提供高伸缩性。支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量。
3、改善数据局部性。允许将数据放入与用户地埋位置相近的地方,从而降低系统延时。
Kafka副本,本质就是一个只能追加写消息的提交日志。根据Kafka副本机制的定义,同一个分区下的所有副本保存有相同的消息序列,这些副本分散保存在不同的Broker上,从而能够对抗部分Broker宕机带来的数据不可用。
1、在Kakfa中,副本分成两类:领导者副本(Leader Replica)和追随者副本(Follower Replica)。每个分区在创建时都要选举一个副本,称为领导者副本,其余的副本自动称为追随者副本。
2、在Kafka中,追随者副本是不对外提供服务的。任何一个追随者副本都不能响应消费者和生产者的读写请求。所有的请求都必须由领导者副本来处理,或者说,所有读写请求都必须发往领导者副本所在的Broker,由该Broker负责处理。追随者副本不处理我客户端请求,它唯一的任务就是从领导者副本异步拉取消息,并写入到自己的提交日志中,从而实现与领导者副本的同步。
3、当领导者副本挂掉了,或者说领导者副本所在的Borker宕机时,Kafka依托于ZK提供的监控功能能够实时感知到,并立即开启新一轮的领导者选举,从追随者副本中选一个作为新的领导者。老Leader副本重启回来后,只能作为追随者副本加入到集群中。
为什么Kafka的追随者副本没有任何作用,它既不能像MySQL那样帮助领导者副本“抗读”,也不能实现将某些副本放到离客户近的地方来改善数据局部性。
1、方便实现“Read-your-writes”。当你使用生产者API向Kafka成功写入消息后,马上使用消费者API去读取刚才生产的消息。
2、方便实现单调读“Monotonic Reads”。就是对于一个消费者用户而言,在多次消费消息时,它不会看到某条消息一会儿存在一会儿不存在。
重平衡:Rebalance
消费者组内某个消费者实例持掉后,其他消费者实例自动重新分配订阅主题分区的过程。
