阿里殷浩大牛写了DDD系统文章,现在已经更新到每四篇,有很多异于常规的地方,收获良多,总结一下
Domain primitive
对于DDD第一讲,作者介绍的Domain primitive,开始有些反感的,对DDD理论也深知一二,但从没听过有这概念,所以觉得作者是挂羊头卖狗肉的,但读完发现原来是对Value object的升华,牛人就是不一样
Domain Primitive的概念和命名来自于Dan Bergh Johnsson & Daniel Deogun的书 Secure by Design,特意找到了这本书的章节,https://livebook.manning.com/book/secure-by-design/chapter-5/1,有兴趣可以看看
对于DP,在《代码大全》中指出过类似概念:ADT
抽象数据类型ADT是指一些数据以及对这些数据所进行的操作的集合
关于使用ADT的建议:
- 把常见的底层数据类型创建为ADT并且使用这些ADT,而不再使用底层数据类型
- 把像文件这样的常用对象当成ADT
- 简单的事物也可以当做ADT:这样可以提高代码的自我说明能力,让代码更容易修改。
- 不要让ADT依赖于其存储介质
ADT就是业务上的最小类型,不要去使用编程语言提供的基础类型
在之前的DDD文章中,也指出很多时候的重构不过是大方法拆分成小方法,更SRP一些,其实也什么意义,DDD带来的好处是业务语义显现化,而DP就是一种手段
使用DP后代码遵循了 DRY 原则和单一性原则,作者从四个维度提出DP带来的好处:接口的清晰度(可阅读性)、数据验证和错误处理、业务逻辑代码的清晰度、和可测试性
在实际项目中碰到一个有意义的问题,我们通过OCR接受识别的增值税发票信息
之前的接口是receiveInvoice(String invoiceCode,String invoiceNo,String checkCode,…),接受OCR给的发票结构化信息
发票号码和发票代码是有业务语义,是业务的最小类型,invoiceCode可以从String升级为InvoiceCode
接口变成:receiveInvoice(InvoiceCode invoiceCode,InvoiceNo invoiceNo,CheckCode checkCode),把业务最小单元提取出来了,接口清晰度,业务语义也显现了。可有个有意思的地方,OCR会出错的,一个正常的发票号码是8位,但会被识别成9位,业务上不能是InvoiceNo,可得固化存储这个识别结果,因此这个入口不能过于语义,总不能来一个WrongInvoiceNo
这儿我可能有个误区,把DP作为有语义的数据验证工具类使用了,可DP应该是Value object的升华,得在domain层使用,参数校验还得用Validate
定义
Domain Primitive 是一个在特定领域里,拥有精准定义的、可自我验证的、拥有行为的 Value Object 。
- DP是一个传统意义上的Value Object,拥有Immutable的特性
- DP是一个完整的概念整体,拥有精准定义
- DP使用业务域中的原生语言
- DP可以是业务域的最小组成部分、也可以构建复杂组合
原则
- 将隐性的概念显性化(Make Implicit Concepts Explicit)
- 将隐性的上下文显性化(Make Implicit Context Explicit)
- 封装多对象行为(Encapsulate Multi-Object Behavior)
VS Value Object
在 Evans 的 DDD 蓝皮书中,Value Object 更多的是一个非 Entity 的值对象
在Vernon 的 DDD红皮书中,作者更多的关注了Value Object的Immutability、Equals方法、Factory方法等
Domain Primitive 是 Value Object 的进阶版,在原始 VO 的基础上要求每个 DP 拥有概念的整体,而不仅仅是值对象。在 VO 的 Immutable 基础上增加了 Validity 和行为。当然同样的要求无副作用(side-effect free)
VS DTO
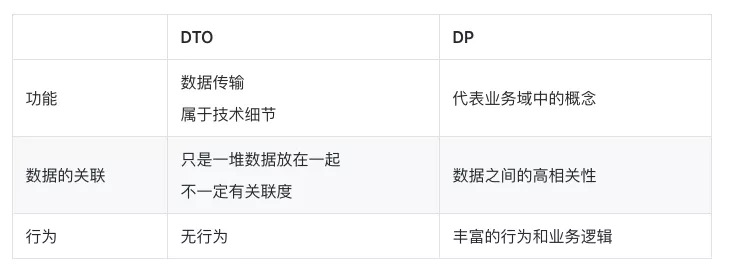
应用架构
这一篇算是正常篇,很多文章都是这样的,也是以银行转账为例,但分析得更特彻
应用架构,意指软件系统中固定不变的代码结构、设计模式、规范和组件间的通信方式
一个好的架构应该需要实现以下几个目标:
- 独立于框架:架构不应该依赖某个外部的库或框架,不应该被框架的结构所束缚
- 独立于UI:前台展示的样式可能会随时发生变化
- 独立于底层数据源:无论使用什么数据库,软件架构不应该因不同的底层数据储存方式而产生巨大改变
- 独立于外部依赖:无论外部依赖如何变更、升级,业务的核心逻辑不应该随之而大幅变化
- 可测试:无论外部依赖什么样的数据库、硬件、UI或服务,业务的逻辑应该都能够快速被验证正确性
这是很多架构的目标,但想想,一个架构是这样,那还剩下什么,框架没了,数据库没了,对于习惯了CRUD的程序员,什么都没了,我们的架构为了什么。真的就是那个模型,一个软件之所以是这个软件的核心模型,也就是domain
DDD是一种设计范式,主张以领域模型为中心驱动整个软件的设计。在DDD中,业务分析和领域建模是软件开发的关键活动。它不关心软件的架构是怎样的。随着技术的发展,我们可能在新版本中更换软件的架构,但是只要业务没有变更,领域模型就是稳定的,无需改动。
事务脚本弊端
一、可维护性能差
可维护性 = 当依赖变化时,有多少代码需要随之改变
二、可拓展性差
可扩展性 = 做新需求或改逻辑时,需要新增/修改多少代码
三、可测试性能差
可测试性 = 运行每个测试用例所花费的时间 * 每个需求所需要增加的测试用例数量
破坏原则
一、单一原则
二、依赖反转原则
三、开放封闭原则
DDD
如果今天能够重新写这段代码,考虑到最终的依赖关系,我们可能先写Domain层的业务逻辑,然后再写Application层的组件编排,最后才写每个外部依赖的具体实现。这种架构思路和代码组织结构就叫做Domain-Driven Design(领域驱动设计,或DDD)。所以DDD不是一个特殊的架构设计,而是所有Transction Script代码经过合理重构后一定会抵达的终点
这段话一针见血,很多时候在讨论DDD时,只是学习战术,什么实体、值对象、聚合,可在做项目时,引入了这些器,其他还不是CRUD,谁真正想过domain,并且以此驱动开发
DDD架构能有效解决传统架构中问题:
- 高可维护性:当外部依赖变更时,内部代码只用变更跟外部对接的模块,其他业务逻辑不变
- 高可扩展性:做新功能时,绝大部分代码都能利用,仅需要增加核心业务逻辑即可
- 高可测试性:每个拆分出来的模块都符合单一性原则,绝大部分不依赖框架,可以快速的单元测试,做到100%覆盖
- 代码结构清晰:通过POM module可以解决模块间的依赖关系,所有外接模块都可以单独独立成jar包被复用。当团队形成规范后,可以快速的定位到相关代码

作者的模块划分和依赖关系,细分析之后发现了些妙处
Infrastructure模块包含了Persistence、Messaging、External等模块。比如:Persistence模块包含数据库DAO的实现,包含Data Object、ORM Mapper、Entity到DO的转化类等。Persistence模块要依赖具体的ORM类库,比如MyBatis。如果需要用Spring-Mybatis提供的注解方案,则需要依赖Spring
Persistence从infrastructure剥离出来,解决了之前碰到的循环依赖问题(repository接口在domain层,但现实在infra层,可从maven module依赖讲,domain又是依赖infra模块的)
对于为什么拆分得这么细,是不是也解决这个问题,特意请教了作者,作者回复:
这块儿可拆可不拆,拆的好处是每个模块职责比较简单,但不拆问题也不大的
domain没必要依赖infra啊?domain里自带Repository接口,所以从maven角度来看,infra是依赖domain
infra只依赖application、domain即可。这里面还有一个Start的模块,把infra依赖进来,然后Spring的DI会自动注入的
这里,domain或app依赖的外部的接口而已,这个一般是独立的jar包
这个也可以是ACL里面的Facade,但是具体的调用实现还是infra
之前也思考过,的确得DIP,domain在最下层,infra在上面,但有个问题,把对外部依赖的接口都是放在infra里面的,所以倒置不了,以及之前在《DDD分层》里面提到的
DDD引入repository放在了领域层,一是对应聚合根的概念,二是抽象了数据库访问,,但DDD限界上下文可能不仅限于访问数据库,还可能访问同样属于外部设备的文件、网络与消息队列。为了隔离领域模型与外部设备,同样需要为它们定义抽象的出口端口,这些出口端口该放在哪里呢?如果依然放在领域层,就很难自圆其说。例如,出口端口EventPublisher支持将事件消息发布到消息队列,要将这样的接口放在领域层,就显得不伦不类了。倘若不放在位于内部核心的领域层,就只能放在领域层外部,这又违背了整洁架构思想
对于这段话,发给作者,让他点评了一下,作者回复:
EventPublisher接口就是放在Domain层,只不过namespace不是xxx.domain,而是xxx.messaging之类的
这里面2个概念,一个是maven module怎么搞,一个是什么是Domain层。这两个不是同一件事
Repository、eventpublisher接口再Domain这个module里,但是他们从理论上是infra层的。
我一般的理解:从外部收到的,属于interface层,比如RPC接口、HTTP接口、消息里面的消费者、定时任务等,这些需要转化为Command、Query、Event,然后给到App层。
App主动能去调用到的,比如DB、Message的Publisher、缓存、文件、搜索这些,属于infra层
所以消息相关代码可能会同时存在2层里。这个主要还是看信息的流转方式,都是从interface-》Application-〉infra
Repository模式
这一篇对repository有了更深的了解,之前对repository的认知和实践都太浮浅
- repository只能操作聚合根
- repository类似dao,当作dao使用
- repository是领域层,但从菱形架构中得知,保持领域层的纯洁,放到南向网关
对repository的认知和实践也就这些了,在实践时基本当成dao使用,当然也碰到了想不通的问题
第一点:数据加载与性能平衡问题
repository操作的对象是聚合根,因此加载一个聚合根,就得是一个完整的聚合根,可是有时我们只想加载部分数据,怎么办?
很多人指出依赖懒加载方式来解决,但也有人指出这是通过技术解决设计问题,我也迷茫,到底怎么办呢?写两个方法吧
1 | findOrder(OrderId id);//获取完整的order聚合 |
特别的别扭吧
第二点:更新数据时,只从聚合根操作,那到了repository怎么知道具体操作哪个对象
可能又需要类似第一点,写多个方法了
这些都是很麻烦很现实的问题,为了domain纯洁性,为了DIP而特意加上不合格的repository,是不是更麻烦了呢?
很多时候,其实技术、框架、依赖三方都不怎么变,变得恰恰是domain,产品需求一日三变,难道我们努力的方向有问题?
repository价值
对于这个问题,就是为了DIP吧,作者又重新对比了DAO
DAO的核心价值是封装了拼接SQL、维护数据库连接、事务等琐碎的底层逻辑,让业务开发可以专注于写代码,但是在本质上,DAO的操作还是数据库操作,DAO的某个方法还是在直接操作数据库和数据模型,只是少写了部分代码
在Uncle Bob的《代码整洁之道》一书里,作者用了一个非常形象的描述:
- 硬件(Hardware):指创造了之后不可(或者很难)变更的东西。数据库对于开发来说,就属于”硬件“,数据库选型后基本上后面不会再变,比如:用了MySQL就很难再改为MongoDB,改造成本过高。
- 软件(Software):指创造了之后可以随时修改的东西。对于开发来说,业务代码应该追求做”软件“,因为业务流程、规则在不停的变化,我们的代码也应该能随时变化。
- 固件(Firmware):即那些强烈依赖了硬件的软件。我们常见的是路由器里的固件或安卓的固件等等。固件的特点是对硬件做了抽象,但仅能适配某款硬件,不能通用。所以今天不存在所谓的通用安卓固件,而是每个手机都需要有自己的固件
从上面的描述我们能看出来,数据库在本质上属于“硬件”,DAO 在本质上属于“固件”,而我们自己的代码希望是属于“软件”。但是,固件有个非常不好的特性,那就是会传播,也就是说当一个软件强依赖了固件时,由于固件的限制,会导致软件也变得难以变更,最终让软件变得跟固件一样难以变更
比如我们使用的mybaties,有各种mapper,原来放在dao中,现在放在repository,换汤不换药
我们需要一个模式,能够隔离我们的软件(业务逻辑)和固件/硬件(DAO、DB),让我们的软件变得更加健壮,而这个就是Repository的核心价值
此刻,对菱形架构有点反思,是不是repository就应该是领域层,就是与外界数据来源的隔离,不关心具体是不是数据库,io,都是repository
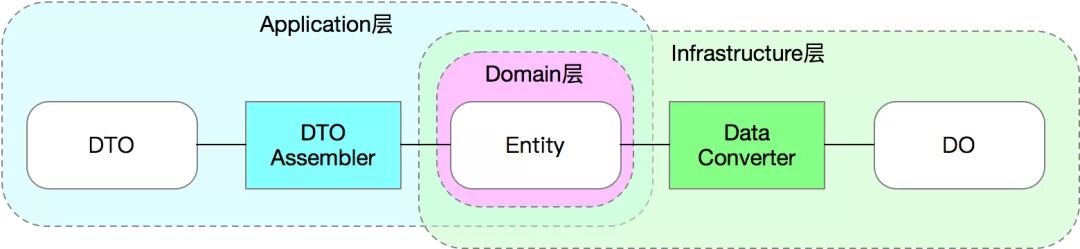
作者把DTOAssembler放在了application层,是不是有点不太合理,至少不太符合分层架构,应该放在controller中呢?
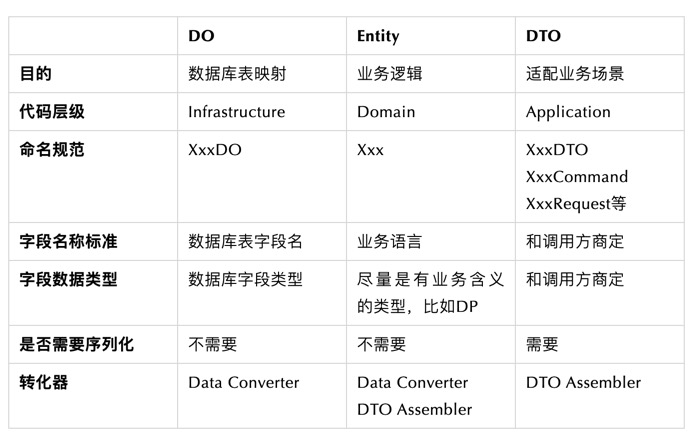
从使用复杂度角度来看,区分了DO、Entity、DTO带来了代码量的膨胀(从1个变成了3+2+N个)。但是在实际复杂业务场景下,通过功能来区分模型带来的价值是功能性的单一和可测试、可预期,最终反而是逻辑复杂性的降低。
repository规范
传统Data Mapper(DAO)属于“固件”,和底层实现(DB、Cache、文件系统等)强绑定,如果直接使用会导致代码“固化”。所以为了在Repository的设计上体现出“软件”的特性,主要需要注意以下三点:
- 接口名称不应该使用底层实现的语法,insert,select,update,delete是sql语法
- 出入参不应该使用底层数据格式,操作的是Aggregate Root,避免底层实现逻辑渗透到业务代码中的强保障
- 应该避免所谓的“通用”repository模式
Change-Tracking 变更追踪
这是很多文章没提过的,这也解决了上面的第二点问题
对于第一点问题,也特意请教了作者,作者这样回复:
在业务系统里,最核心的目标就是要确保数据的一致性,而性能(包括2次数据库查询、序列化的成本)通常不是大问题。如果为了性能而牺牲一致性,就是捡了芝麻漏了西瓜,未来基本上必然会触发bug。
如果性能实在是瓶颈,说明你的设计出了问题,说明你的查询目标(主订单信息)和写入目标(主子订单集合)是不一致的。这个时候一个通常的建议是用CQRS的方式,Read侧读取的可能是另一个存储(可能是搜索、缓存等),然后写侧是用完整的Aggregate来做变更操作,然后通过消息或binlog同步的方式做读写数据同步。
领域层设计规范
这一讲,对领域层讲解得很充分,大牛就是大牛,DDD只是一个外衣,遮挡不了牛人内涵的韵美,这个系列如果不与DDD联系,就取名牛人叫你怎么写代码,也是相当优秀
一直以来我也认为DDD的基础是面向对象思想,我相对认为DDD与面向对象两者交集很大,重合度很高,结果作者这篇让我认知更深刻了,尤其以游戏为示例,让我更加佩服了,毕竟我在游戏业混了很久,一直自认写的代码还不错,也碰到文章指出的一些问题,可没再深入思考更优解决方案
继承
为什么Composition-over-inheritance?以前只知道继承是强耦合,我们的道是高内聚低耦合,所以不要多过使用继承。之前同事讲过行为要多Composition,但数据层面还得inheritance
作者从OCP角度再次解释这个问题
继承虽然可以通过子类扩展新的行为,但因为子类可能直接依赖父类的实现,导致一个变更可能会影响所有对象
继承虽然能Open for extension,但很难做到Closed for modification。所以今天解决OCP的主要方法是通过Composition-over-inheritance,即通过组合来做到扩展性,而不是通过继承
领域服务
作者讲了三种场景的领域服务
单对象策略型
这个示例,很有新意,实在的,没见过这样写的,有点不理解,特地请教了作者
为什么通过Double Dispatch来反转调用领域服务的方法
这里的问题就是你作为服务提供方,没办法保证Weapon入参一定是合法的。在这里依赖了另一个服务的提前校验,就说明Player没有做校验,那如果因为忘记或者bug没有提前校验呢?
在这里Entity的设计理念是要强保证一致性,这也是为什么要让服务通过参数注入
可能这是事务脚本思维的原因,先判断再执行,而作者的意思是执行本身就应该包含判断,是个整体,不能分两步
跨对象事务型
这个常见,领域服务就是这样来的
Player.attack(monster) 还是 Monster.receiveDamage(Weapon, Player)?放在领域服务就行了
通用组件型
这个平常大多被Utils类给取代了
但如果再增加一个跳跃能力Jumpable呢?一个跑步能力Runnable呢?如果Player可以Move和Jump,Monster可以Move和Run,怎么处理继承关系?要知道Java(以及绝大部分语言)是不支持多父类继承的,所以只能通过重复代码来实现
这个问题,最近在项目正好又碰到了,java继承没法处理,只能接口化处理
但在实体上都得实现相应接口,有些重复,对此也特地请教了作者:

MovementSystem可以共用,但这些实体类都实现Movable,也得重复实现,这个情况是不是没法避免
这个是很正常的,Movable本来就应该是说“我能够Move”,然后要Move就必须要有Position和Velocity。所以在Entity层面重复实现是必须的。只要是接口编程就必然需要这样(除非走mixin,但那个Java不支持)。没办法走Base类就是因为要避免继承,同时base类也没办法实现多父继承。
在有Mixin的语言里理论上是可以避免这种,但是Mixin有自己的问题,同时我们主流编程语言都没有mixin
OOP、ECS、DDD三者的比较:
- 基于继承关系的OOP代码:OOP的代码最好写,也最容易理解,所有的规则代码都写在对象里,但是当领域规则变得越来越复杂时,其结构会限制它的发展。新的规则有可能会导致代码的整体重构。
- 基于组件化的ECS代码:ECS代码有最高的灵活性、可复用性、及性能,但极具弱化了实体类的内聚,所有的业务逻辑都写在了服务里,会导致业务的一致性无法保障,对商业系统会有较大的影响。
- 基于领域对象 + 领域服务的DDD架构:DDD的规则其实最复杂,同时要考虑到实体类的内聚和保证不变性(Invariants),也要考虑跨对象规则代码的归属,甚至要考虑到具体领域服务的调用方式,理解成本比较高。
实体类
在这个过程中,作者也随带说了些实体的规范
因为 Weapon 是实体类,但是Weapon能独立存在,Player不是聚合根,所以Player只能保存WeaponId,而不能直接指向Weapon;
这是对象之间关系的处理,都是这样推荐的,不要对象对联,使用ID关联。但聚合根可以直接对象关联
Entity只能保留自己的状态(或非聚合根的对象)。任何其他的对象,无论是否通过依赖注入的方式弄进来,都会破坏Entity的Invariance,并且还难以单测
对于为什么实体都特地加一个业务实体ID,之前学习有介绍:
身份标识(Identity,或简称为 ID)是实体对象的必要标志,换言之,没有身份标识的领域对象就不是实体。实体的身份标识就好像每个公民的身份证号,用以判断相同类型的不同对象是否代表同一个实体。身份标识除了帮助我们识别实体的同一性之外,主要的目的还是为了管理实体的生命周期。实体的状态是可以变更的,这意味着我们不能根据实体的属性值进行判断,如果没有唯一的身份标识,就无法跟踪实体的状态变更,也就无法正确地保证实体从创建、更改到消亡的生命过程。
一些实体只要求身份标识具有唯一性即可,如评论实体、博客实体或文章实体的身份标识,都可以使用自动增长的 Long 类型或者随机数与 UUID、GUID,这样的身份标识并没有任何业务含义。有些实体的身份标识则规定了一定的组合规则,例如公民实体、员工实体与订单实体的身份标识就不是随意生成的。遵循业务规则生成的身份标识体现了领域概念,例如公民实体的身份标识其实就是“身份证号”这一领域概念。定义规则的好处在于我们可以通过解析身份标识获取有用的领域信息,例如解析身份证号,可以直接获得该公民的部分基础信息,如籍贯、出生日期、性别等,解析订单号即可获知该订单的下单渠道、支付渠道、业务类型与下单日期等。
在设计实体的身份标识时,通常可以将身份标识的类型分为两个层次:通用类型与领域类型。通用类型提供了系统所需的各种生成唯一标识的类型,如基于规则的标识、基于随机数的标识、支持分布式环境唯一性的标识等。这些类型都将放在系统层代码模型的 domain 包中,可以作为整个系统的共享内核
总结
大牛写的文章就是深入浅出,丰富饱满,还是多拜读,多温故,不是因为DDD他们变得这么优秀,而是他们本身就很优秀,也许他们心中早有DDD了,只是没有DDD这个名字而已
希望有一天我也能写出这么好的文章
