没有一身好内功,招式再多都是空;算法绝对是防身必备,面试时更是不可或缺;跟着算法渣一起从零学算法
定义
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”
算法
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。
演示
对数组[5,6,3,1,8,7,2,4]进行冒泡排序
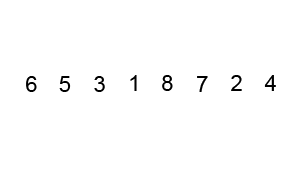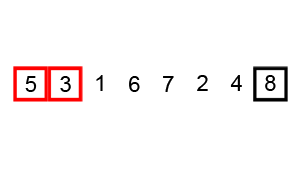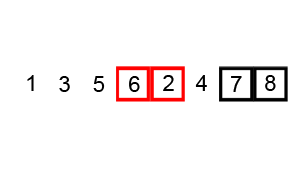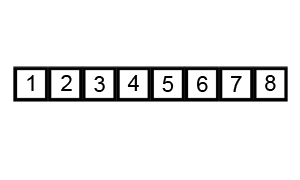
1 | /** |
改进
有序
如果一个数组本身就是有序的,或者部分已经有序
比如:[8,7,6,5,4,3,1,2]
假如现在有一个长度10000的数组,前1000无序,后9000有序并且大于前1000数据。用上面这种方法,数据交换次数在1000之内,但是剩下9000的数据虽然没有交换,但是每次循环都会进行比较。剩下9000数据已经有序了,我们不要对它们去进行判断浪费不必要的时间
1 | /** |
鸡尾酒排序
鸡尾酒排序等于是冒泡排序的轻微变形。不同的地方在于从低到高然后从高到低,而冒泡排序则仅从低到高去比较序列里的每个元素。他可以得到比冒泡排序稍微好一点的效能,原因是冒泡排序只从一个方向进行比对(由低到高),每次循环只移动一个项目。
算法
1 | /** |
总体上,鸡尾酒排序可以获得比冒泡排序稍好的性能。但是完全逆序时,鸡尾酒排序与冒泡排序的效率都非常差
时间复杂度
如果我们的数据正序,只需要走一趟即可完成排序。所需的比较次数C和记录移动次数M均达到最小值,即:Cmin=n-1;Mmin=0;所以,冒泡排序最好的时间复杂度为O(n)。
如果很不幸我们的数据是反序的,则需要进行n-1趟排序。每趟排序要进行n-i次比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
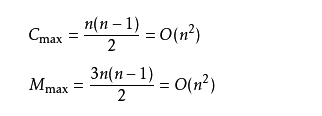
| Best | Average | Worst | Memory | Stable |
|---|---|---|---|---|
| n | n^2 | n^2 | 1 | Stable |
